【计算机视觉】霍夫线/圆变换从原理到源码详解
---恢复内容开始---
@[toc]
# 1 简述
霍夫变换是一个经典的特征提取技术,本文主要说的是霍夫线/圆变换,即从图像中获取直线与圆,同时需要对图像进行二值化操作,效果如下。
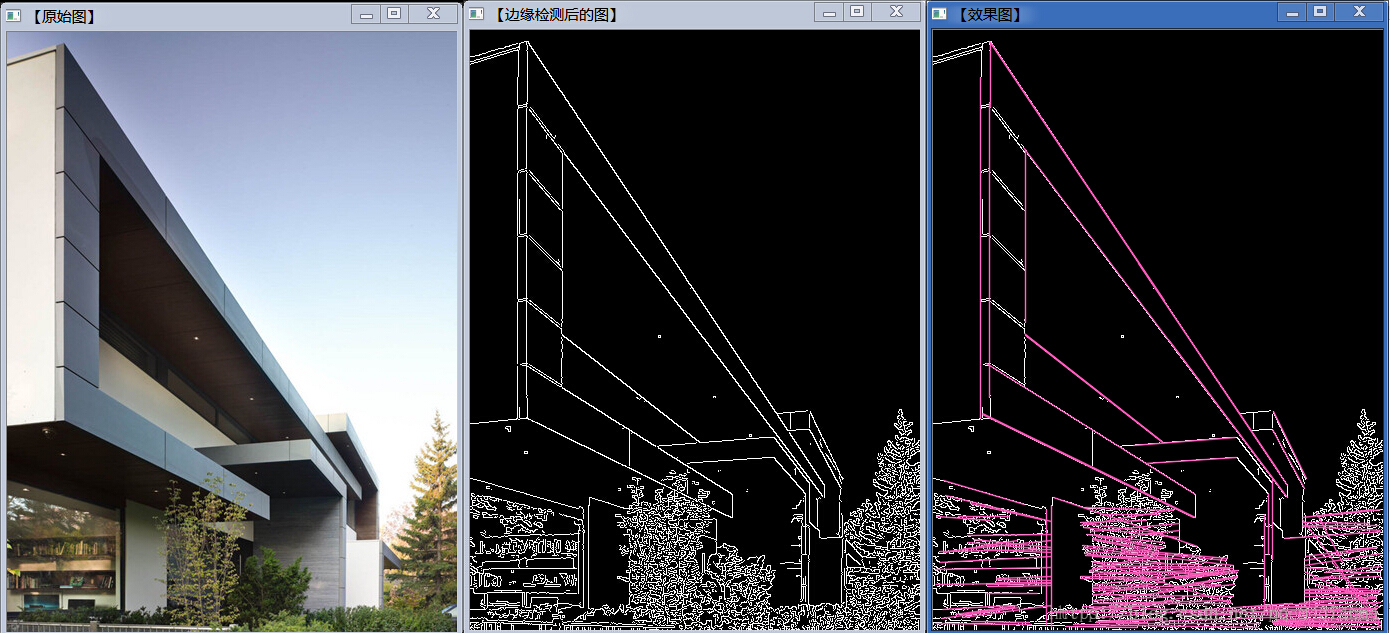
霍夫变换目的通过投票程序在特定类型的形状内找到对象的不完美示例,这个投票程序是在一个参数空间中进行的,在这个参数空间中,候选对象被当作所谓的累加器空间中的局部最大值来获得,所述累加器空间由用于计算霍夫变换的算法明确的构建,霍夫变换不仅能够识别出图像中有无需要检测的图形,而且能够定位到该图像(包括位置、角度等),有标准霍夫变换,多尺度霍夫变换,统计概率霍夫变换3种较为经典的方法,主要优点是能容忍特征边界描述中的间隙,并且相对不受图像噪声的影响。
2 标准霍夫线变换原理
2.1 霍夫变换直线的方程
直线的方程形式有截距式,斜截式,一般式,点斜式等,但是这些形式都有“奇异”情况,其中一个截距为0,斜率为0, c=0(通常把c除到等式左面,减少一个参数的搜索),另外某些形式的参数空间不是闭的,比如斜截式的斜率k,取值范围从0到无穷大,给量化搜索带来了困难。所以在霍夫线变换中采用了如下方程的形式:
\[p = xcos\theta + ysin\theta
\]
其中\(p\)与\(\theta\)都是极坐标下点的极径与极角(也可以理解\(p\)是原点离直线最近的距离),但并不是极坐标方程,因为还在笛卡尔坐标下表示,两个参数的意义如下图:
这个方程的巧妙之处是角度与距离这两个参数都是有界的,而且没有奇异的情况,因此可以在参数空间中进行搜索。同时,直线霍夫变换有2个参数通过这一个等式相关联,所以程序在投票阶段只需要遍历其中一个,通过等式获取另一个参数从而进行投票与搜索峰值。
2.2 霍夫空间
对于直线来说,可以将图像的每一条直线与一对参数\((p, \theta)\)相关联,这个参数\((p, \theta)\)平面有时被称为霍夫空间,用于二维直线的集合,因此,对于某一指定的点,不同的\((p, \theta)\)代表了不同的直线,我们把\((p, \theta)\)之间的关系通过图像表示出来——固定一个点(3,4),角度取[0,2\(\pi\)]时,\(r\)的范围取值情况:
会发现曲线的形状类似一条正弦曲线,通常\(p\)越大,正弦曲线的振幅越大,反而就会越小。
2.3 检测直线的方法
可以得到一个结论,给定平面中的单个点,那么通过该点的所有直线的集合对应于(r,θ)平面中的正弦曲线,这对于该点是独特的。一组两个或更多点形成一条直线将产生在该线的(r,θ)处交叉的一条或多条正弦曲线。因此,检测共线点的问题可以转化为找到并发曲线的问题。
具体的,通过将霍夫参数空间量化为有限间隔或累加器单元来实现变换。随着算法的运行,每个算法都把\((x_{i}, y_{i})\)转换为一个离散化的 \((r,θ)\)曲线,并且沿着这条曲线的累加器单元被递增。累加器阵列中产生的峰值表示图像中存在相应的直线的有力证据。 换句话说,将每个交点看成一次投票,也就是说\(A(r,θ)=A(r,θ)+1\),所有点都如此进行计算后,可以设置一个阈值,投票大于这个阈值的可以认为是找到的直线。
2.4 一个例子
举一个具体的例子,来体现霍夫变换的流程同时更深的理解一下该算法(此例子摘取某博客,下文会给出所有参考博客的链接)
霍夫变换可用于识别最适合一组给定边缘点的曲线的参数。该边缘描述通常从诸如Roberts Cross,Sobel或 Canny边缘检测器的特征检测算子获得,并且可能是嘈杂的,即其可能包含对应于单个整体特征的多个边缘片段。此外,由于边缘检测器的输出仅限定图像中的特征的位置,所以霍夫变换进一步是确定两个特征是什么(即检测其具有参数(或其他)的特征描述)以及 它们有多少个存在于图像中。
为了详细说明霍夫变换,我们从两个闭合矩形的简单图像开始。
使用 Canny边缘检测器可产生一组边界描述的这个部分,如下图:
这里我们看到了图像中的整体边界,但是这个结果并没有告诉我们边界描述中的特征的身份(和数量)。在这种情况下,我们可以使用Hough(线检测)变换来检测该图像的八个单独的直线段,从而确定对象的真实几何结构。
如果我们使用这些边缘/边界点作为Hough变换的输入,每一个点通过遍历不同的\((r, \theta)\)都会在笛卡尔空间中生成一条曲线,当被视为强度图像时, 累加器阵列看起来像如下所示:
可以利用直方图均衡技术使得图像可以让我们看到包含在低强度像素值中的信息模式,如下图:
注意,虽然r和θ是概念上的极坐标,但是累加器空间以横坐标θ和纵坐标r的矩形绘制 。请注意,累加器空间环绕图像的垂直边缘,因此实际上只有8个实际峰值。
由梯度图像中的共线点生成的曲线(r,θ) 在霍夫变换空间中的峰中相交。这些交点表征原始图像的直线段。有许多方法可用于从累加器阵列中提取这些亮点或局部最大值。例如,一个简单的方法涉及阈值处理,然后 对累加器阵列图像中孤立的亮点集群进行一些细化处理。这里我们使用相对阈值来提取(r,θ) ,对应于原始图像中的每条直线边缘的点。(换句话说,我们只采用累加器数组中的那些局部最大值,其值等于或大于全局最大值的某个固定百分比。)
从Hough变换空间(即,反霍夫变换)映射回笛卡尔空间产生一组图像主题的线描述。通过将该图像叠加在原始的反转版本上,我们可以确认霍夫变换找到两个矩形的8个真实边的结果,并且因此展示出了遮挡场景的基础几何形状。
请注意,在这个简单的例子中,检测到的和原始图像线的对齐精度显然不完美,这取决于累加器阵列的量化。(还要注意许多图像边缘有几条检测线,这是因为有几个附近的霍夫空间峰值具有相似的线参数值,存在控制这种效应的技术,但这里没有用来说明标准霍夫变换)
还要注意,由霍夫变换产生的线条的长度是无限的。如果我们希望识别产生变换参数的实际线段,则需要进一步的图像分析以便查看这些无限长线的哪些部分实际上具有点。
为了说明Hough技术对噪声的鲁棒性,Canny边缘描述已被破坏1%(由椒盐噪声引起), 在Hough变换之前,如图12所示。
霍夫空间如下图所示:
将这个结果反霍夫变换(相对阈值设置为40%,并将它覆盖在原来的结果上)
可以通过变换图像来研究Hough变换对特征边界中的间隙的敏感性,如下图:
然后我们再将其变换到霍夫变换空间,如下图
然后使用40%的相对阈值去对图像反霍夫变换(同样也是叠加在原图上)
在这种情况下,因为累加器空间没有接收到前面例子中的条目数量,只能找到7个峰值,但这些都是结构相关的线。
3 霍夫线变换的算法流程
3.1 标准霍夫线变换算法流程
读取原始图像,并转换成灰度图,利用阈值分割或者边缘检测算子转换成二值化边缘图像
初始化霍夫空间, 令所有\(Num(\theta, p) = 0\)
对于每一个像素点\((x, y)\),在参数空间中找出所有满足\(xcos\theta + ysin\theta = p\)的\((\theta, p)\)对,然后令\(Num(\theta, p) = Num(\theta, p) + 1\)
统计所有\(Num(\theta, p)\)的大小,取出\(Num(\theta, p) > τ\)的参数(\(τ\)是所设的阈值),从而得到一条直线。
将上述流程取出的直线,确定与其相关线段的起始点与终止点(有一些算法,如蝴蝶形状宽度,峰值走廊之类)
3.2 统计概率霍夫变换算法流程
标准霍夫变换本质上是把图像映射到它的参数空间上,它需要计算所有的M个边缘点,这样它的运算量和所需内存空间都会很大。如果在输入图像中只是处理\(m(m HoughLinesP函数就是利用概率霍夫变换来检测直线的。它的一般步骤为: 随机抽取图像中的一个特征点,即边缘点,如果该点已经被标定为是某一条直线上的点,则继续在剩下的边缘点中随机抽取一个边缘点,直到所有边缘点都抽取完了为止; 对该点进行霍夫变换,并进行累加和计算; 选取在霍夫空间内值最大的点,如果该点大于阈值的,则进行步骤4,否则回到步骤1; 根据霍夫变换得到的最大值,从该点出发,沿着直线的方向位移,从而找到直线的两个端点; 计算直线的长度,如果大于某个阈值,则被认为是好的直线输出,回到步骤1。 4 OpenCV中的霍夫变换函数 4.1标准霍夫变换HoughLines()函数 void HoughLines(InputArray image,OutputArray lines, double rho, double theta, int threshold, double srn=0,double stn=0 ) 第一个参数,InputArray类型的image,输入图像,即源图像,需为8位的单通道二进制图像,可以将任意的源图载入进来后由函数修改成此格式后,再填在这里。 第二个参数,InputArray类型的lines,经过调用HoughLines函数后储存了霍夫线变换检测到线条的输出矢量。每一条线由具有两个元素的矢量\((p, \theta)\)表示,其中,\(p\)是离坐标原点((0,0)(也就是图像的左上角)的距离。 \(\theta\)是弧度线条旋转角度(0垂直线,π/2水平线)。 第三个参数,double类型的rho,以像素为单位的距离精度。另一种形容方式是直线搜索时的进步尺寸的单位半径。PS:Latex中/rho就表示 \(\rho\)。 第四个参数,double类型的theta,以弧度为单位的角度精度。另一种形容方式是直线搜索时的进步尺寸的单位角度。 第五个参数,int类型的threshold,累加平面的阈值参数,即识别某部分为图中的一条直线时它在累加平面中必须达到的值。大于阈值threshold的线段才可以被检测通过并返回到结果中。 第六个参数,double类型的srn,有默认值0。对于多尺度的霍夫变换,这是第三个参数进步尺寸rho的除数距离。粗略的累加器进步尺寸直接是第三个参数rho,而精确的累加器进步尺寸为rho/srn。 第七个参数,double类型的stn,有默认值0,对于多尺度霍夫变换,srn表示第四个参数进步尺寸的单位角度theta的除数距离。且如果srn和stn同时为0,就表示使用经典的霍夫变换。否则,这两个参数应该都为正数。 4.2 统计概率霍夫变换(HoughLinesP) C++: void HoughLinesP(InputArray image, OutputArray lines, double rho, double theta, int threshold, double minLineLength=0, double maxLineGap=0 ) 第一个参数,InputArray类型的image,输入图像,即源图像,需为8位的单通道二进制图像,可以将任意的源图载入进来后由函数修改成此格式后,再填在这里。 第二个参数,InputArray类型的lines,经过调用HoughLinesP函数后后存储了检测到的线条的输出矢量,每一条线由具有四个元素的矢量\((x_1,y_1, x_2, y_2)\)表示,其中,\((x_1, y_1)\)和\((x_2, y_2)\)是每个检测到的线段的结束点。 第三个参数,double类型的rho,以像素为单位的距离精度。另一种形容方式是直线搜索时的进步尺寸的单位半径。 第四个参数,double类型的theta,以弧度为单位的角度精度。另一种形容方式是直线搜索时的进步尺寸的单位角度。 第五个参数,int类型的threshold,累加平面的阈值参数,即识别某部分为图中的一条直线时它在累加平面中必须达到的值。大于阈值threshold的线段才可以被检测通过并返回到结果中。 第六个参数,double类型的minLineLength,有默认值0,表示最低线段的长度,比这个设定参数短的线段就不能被显现出来。 第七个参数,double类型的maxLineGap,有默认值0,允许将同一行点与点之间连接起来的最大的距离。 5 源码分析 此部分参考几位博主的博客,更改了里面一些我认为不太对的地方以及加上了一些自己的理解还有就是一些没有解释的地方 5.1 HoughLines()源码分析 阅读源码之后,发现源码确实细节方面做得比较好,无论是内存方面,还是效率方面,包括一些小细节,比如避免除法,等等。所以源码值得借鉴与反复参考,具体解释如下。 static void icvHoughLinesStandard( const CvMat* img, float rho, float theta, int threshold, CvSeq *lines, int lineMax) { cv::AutoBuffer cv::AutoBuffer const uchar* image; int step, width, height; int numangle, numrho; int total=0; float ang; int r, n; int i, j; float irho = 1 / rho; double scale; //再次确保输入图像的正确性 CV_Assert( CV_IS_MAT(img) && CV_MAT_TYPE(img->type) == CV_8UC1); image = img->data.ptr; //得到图像的指针 step = img->step; //得到图像的步长(通道) width = img->cols; //得到图像的宽 height = img->rows; //得到图像的高 //由角度和距离的分辨率得到角度和距离的数量,即霍夫变换后角度和距离的个数 numangle = cvRound(CV_PI / theta); // 霍夫空间,角度方向的大小 numrho = cvRound(((width + height)*2 + 1) / rho); //r的空间范围, 这里以周长作为rho的上界 /* allocator类是一个模板类,定义在头文件memory中,用于内存的分配、释放、管理,它帮助我们将内存分配和对象构造分离开来。具体地说,allocator类将内存的分配和对象的构造解耦, 分别用allocate和construct两个函数完成,同样将内存的释放和对象的析构销毁解耦,分别用deallocate和destroy函数完成。 */ //为累加器数组分配内存空间 //该累加器数组其实就是霍夫空间,它是用一维数组表示二维空间 _accum.allocate((numangle+2) * (numrho + 2)); //为排序数组分配内存空间 _sort_buf.allocate(numangle * numrho); //为正弦和余弦列表分配内存空间 _tabSin.allocate(numangle); _tabCos.allocate(numangle); //分别定义上述内存空间的地址指针 int *accum = _accum, *sort_buf = _sort_buf; int *tabSin = _tabSin, *tabCos = _tabCos; //累加器数组清零 memset( accum, 0, sizeof(accum[0]) * (numangle+2) * (numrho+2) ); //为避免重复运算,事先计算好sinθi/ρ和cosθi/ρ for( ang = 0, n = 0; n < numangle; ang += theta, n++ ) //计算正弦曲线的准备工作,查表 { tabSin[n] = (float)(sin(ang) * irho); tabCos[n] = (float)(cos(ang) * irho); } //stage 1. fill accumulator //执行步骤1,逐点进行霍夫空间变换,并把结果放入累加器数组内 for( i = 0 ; i < height; i++) for( j = 0; j < width; j++) { //只对图像的非零值处理,即只对图像的边缘像素进行霍夫变换 if( image[i * step + j] != 0 ) //将每个非零点,转换为霍夫空间的离散正弦曲线,并统计。 for( n = 0; n < numangle; n++ ) { //根据公式: ρ = xcosθ + ysinθ //cvRound()函数:四舍五入 r = cvRound( j * tabCos[n] + i * tabSin[n]); //numrho是ρ的最大值,或者说最大取值范围 r += (numrho - 1) / 2; //因为theta是从0到π的,所以cos(theta)是有负的,所以就所有的r += 最大值的一半,让极径都>0 //另一方面,这也预防了r小于0,让本属于这一行的点跑到了上一行,这样可能导致同一个位置却表示了多个不同的“点” //r表示的是距离,n表示的是角点,在累加器内找到它们所对应的位置(即霍夫空间内的位置),其值加1 accum[(n+1) * (numrho+2)+ r + 1]++; /* 将1维数组想象成2维数组 n+1是为了第一行空出来 numrho+2 是总共的列数,这里实际意思应该是半径的所有可能取值,加2是为了防止越界,但是说成列数我觉得也没错,并且我觉得这样比较好理解 r+1 是为了把第一列空出来 因为程序后面要比较前一行与前一列的数据, 这样省的越界 因此空出首行和首列*/ } } // stage 2. find local maximums // 执行步骤2,找到局部极大值,即非极大值抑制 // 霍夫空间,局部最大点,采用四领域判断,比较。(也可以使8邻域或者更大的方式),如果不判断局部最大值,同时选用次大值与最大值,就可能会是两个相邻的直线,但实际是一条直线。 // 选用最大值,也是去除离散的近似计算带来的误差,或合并近似曲线。 for( r = 0 ; r < numrho; r++ ) for( n = 0; n < numangle; n++ ) { //得到当前值在累加器数组的位置 int base = (n+1)*(numrho+2) + r + 1; //得到计数值,并以它为基准,看看它是不是局部极大值 if( accum[base] > threshold && accum[base] > accum[base - 1] && accum[base] >= accum[base+1] && accum[base] > accum[base - numrho - 2] && accum[base] >= accum[base + numrho + 2) //把极大值位置存入排序数组内——sort_buf sort_buf[total++] = base; } //stage 3. sort the detected lines by accumulator value //执行步骤3,对存储在sort_buf数组内的累加器的数据按由大到小的顺序进行排序 icvHoughSortDescent32s( sort_buf, total, accum ); /*OpenCV中自带了一个排序函数,名称为: void icvHoughSortDescent32s(int *sequence , int sum , int*data),参数解释: 第三个参数:数组的首地址 第二个参数:要排序的数据总数目 第一个参数:此数组存放data中要参与排序的数据的序号 而且这个排序算法改变的只是sequence[]数组中的元素,源数据data[]未发生丝毫改变。 */ // stage 4. store the first min(total, linesMax ) lines to the output buffer,输出直线 lineMax = MIN(lineMax, total); //linesMax是输入参数,表示最多输出几条直线 //事先定义一个尺度 scale = 1./(numrho+2); for(i=0; i { //CvLinePolar 直线的数据结构 //CvLinePolar结构在该文件的前面被定义 CvLinePolar line; //idx为极大值在累加器数组的位置 int idx = sort_buf[i]; //找到索引(下标) //分离出该极大值在霍夫空间中的位置 //因为n是从0开始的,而之前为了防止越界,所以将所有的n+1了,因此下面要-1,同理r int n = cvFloor(idx*scale) - 1; //向下取整 int r = idx - (n+1)*(numrho+2) - 1; //最终得到极大值所对应的角度和距离 line.rho = (r - (numrho - 1)*0.5f)*rho; //因为之前统一将r+= (numrho-1)/2, 因此需要还原以获得真实的rho line.angle = n * theta; //存储到序列内 cvSeqPush( lines, &line ); //用序列存放多条直线 } } 5.2 HoughLinesP源码分析 这个代码与之前HoughLines风格完全不同,个人感觉没有之前HoughLines的优美,同时小优化也并不是特别注意,不过实现算法思想的大体思路还是值得我这个初学者借鉴的,但是里面那个shitf操作没看懂,不是很理解,如果有同学会的话,希望解释一下 static void icvHoughLinesProbabilistic( CvMat* image, float rho, float theta, int threshold, int lineLength, int lineGap, CvSeq *lines, int linesMax ) { //accum为累加器矩阵,mask为掩码矩阵 cv::Mat accum, mask; cv::vector //开辟一段内存空间 cv::MemStorage storage(cvCreateMemStorage(0)); //用于存储特征点坐标,即边缘像素的位置 CvSeq* seq; CvSeqWriter writer; int width, height; //图像的宽和高 int numangle, numrho; //角度和距离的离散数量 float ang; int r, n, count; CvPoint pt; float irho = 1 / rho; //距离分辨率的倒数 CvRNG rng = cvRNG(-1); //随机数 const float* ttab; //向量trigtab的地址指针 uchar* mdata0; //矩阵mask的地址指针 //确保输入图像的正确性 CV_Assert( CV_IS_MAT(image) && CV_MAT_TYPE(image->type) == CV_8UC1 ); width = image->cols; //提取出输入图像的宽 height = image->rows; //提取出输入图像的高 //由角度和距离分辨率,得到角度和距离的离散数量 numangle = cvRound(CV_PI / theta); numrho = cvRound(((width + height) * 2 + 1) / rho); //创建累加器矩阵,即霍夫空间 accum.create( numangle, numrho, CV_32SC1 ); //创建掩码矩阵,大小与输入图像相同 mask.create( height, width, CV_8UC1 ); //定义trigtab的大小,因为要存储正弦和余弦值,所以长度为角度离散数的2倍 trigtab.resize(numangle*2); //累加器矩阵清零 accum = cv::Scalar(0); //避免重复计算,事先计算好所需的所有正弦和余弦值 for( ang = 0, n = 0; n < numangle; ang += theta, n++ ) { trigtab[n*2] = (float)(cos(ang) * irho); trigtab[n*2+1] = (float)(sin(ang) * irho); } //赋值首地址 ttab = &trigtab[0]; mdata0 = mask.data; //开始写入序列 cvStartWriteSeq( CV_32SC2, sizeof(CvSeq), sizeof(CvPoint), storage, &writer ); // stage 1. collect non-zero image points //收集图像中的所有非零点,因为输入图像是边缘图像,所以非零点就是边缘点 for( pt.y = 0, count = 0; pt.y < height; pt.y++ ) { //提取出输入图像和掩码矩阵的每行地址指针 const uchar* data = image->data.ptr + pt.y*image->step; // step是每一行的字节大小 此行代码就转到当前遍历的这一行 uchar* mdata = mdata0 + pt.y*width; for( pt.x = 0; pt.x < width; pt.x++ ) { if( data[pt.x] ) //是边缘点 { mdata[pt.x] = (uchar)1; //掩码的相应位置置1 CV_WRITE_SEQ_ELEM( pt, writer ); 把该坐标位置写入序列 } else //不是边缘点 mdata[pt.x] = 0; //掩码的相应位置清0 } } //终止写序列,seq为所有边缘点坐标位置的序列 seq = cvEndWriteSeq( &writer ); count = seq->total; //得到边缘点的数量 // stage 2. process all the points in random order //随机处理所有的边缘点 for( ; count > 0; count-- ) { // choose random point out of the remaining ones //步骤1,在剩下的边缘点中随机选择一个点,idx为不大于count的随机数 int idx = cvRandInt(&rng) % count; //max_val为累加器的最大值,max_n为最大值所对应的角度 int max_val = threshold-1, max_n = 0; //由随机数idx在序列中提取出所对应的坐标点 CvPoint* point = (CvPoint*)cvGetSeqElem( seq, idx ); //定义直线的两个端点 CvPoint line_end[2] = {{0,0}, {0,0}}; float a, b; //累加器的地址指针,也就是霍夫空间的地址指针 int* adata = (int*)accum.data; int i, j, k, x0, y0, dx0, dy0, xflag; int good_line; const int shift = 16; // //提取出坐标点的横、纵坐标 i = point->y; j = point->x; // "remove" it by overriding it with the last element //用序列中的最后一个元素覆盖掉刚才提取出来的随机坐标点 *point = *(CvPoint*)cvGetSeqElem( seq, count-1 ); // check if it has been excluded already (i.e. belongs to some other line) //检测这个坐标点是否已经计算过,也就是它已经属于其他直线 //因为计算过的坐标点会在掩码矩阵mask的相对应位置清零 if( !mdata0[i*width + j] ) //该坐标点被处理过 continue; //不做任何处理,继续主循环 // update accumulator, find the most probable line //步骤2,更新累加器矩阵,找到最有可能的直线 for( n = 0; n < numangle; n++, adata += numrho ) { //由角度计算距离 r = cvRound( j * ttab[n*2] + i * ttab[n*2+1] ); r += (numrho - 1) / 2; //防止r为负数 //在累加器矩阵的相应位置上数值加1,并赋值给val int val = ++adata[r]; //更新最大值,并得到它的角度 if( max_val < val ) { max_val = val; max_n = n; } } // if it is too "weak" candidate, continue with another point //步骤3,如果上面得到的最大值小于阈值,则放弃该点,继续下一个点的计算 if( max_val < threshold ) continue; // from the current point walk in each direction // along the found line and extract the line segment //步骤4,从当前点出发,沿着它所在直线的方向前进,直到达到端点为止 a = -ttab[max_n*2+1]; //a=-sinθ b = ttab[max_n*2]; //b=cosθ //当前点的横、纵坐标值 x0 = j; y0 = i; //确定当前点所在直线的角度是在45度~135度之间,还是在0~45或135度~180度之间 if( fabs(a) > fabs(b) ) //在45度~135度之间 { xflag = 1; //置标识位,标识直线的粗略方向 //确定横、纵坐标的位移量 dx0 = a > 0 ? 1 : -1; dy0 = cvRound( b*(1 << shift)/fabs(a) ); //确定纵坐标 y0 = (y0 << shift) + (1 << (shift-1)); } else //在0~45或135度~180度之间 { xflag = 0; //清标识位 //确定横、纵坐标的位移量 dy0 = b > 0 ? 1 : -1; dx0 = cvRound( a*(1 << shift)/fabs(b) ); //确定横坐标 x0 = (x0 << shift) + (1 << (shift-1)); } //搜索直线的两个端点 for( k = 0; k < 2; k++ ) { //gap表示两条直线的间隙,x和y为搜索位置,dx和dy为位移量 int gap = 0, x = x0, y = y0, dx = dx0, dy = dy0; //搜索第二个端点的时候,反方向位移 if( k > 0 ) dx = -dx, dy = -dy; // walk along the line using fixed-point arithmetics, // stop at the image border or in case of too big gap //沿着直线的方向位移,直到到达图像的边界或大的间隙为止 for( ;; x += dx, y += dy ) { uchar* mdata; int i1, j1; //确定新的位移后的坐标位置 if( xflag ) { j1 = x; i1 = y >> shift; } else { j1 = x >> shift; i1 = y; } //如果到达了图像的边界,停止位移,退出循环 if( j1 < 0 || j1 >= width || i1 < 0 || i1 >= height ) break; //定位位移后掩码矩阵位置 mdata = mdata0 + i1*width + j1; // for each non-zero point: // update line end, // clear the mask element // reset the gap //该掩码不为0,说明该点可能是在直线上 if( *mdata ) { gap = 0; //设置间隙为0 //更新直线的端点位置 line_end[k].y = i1; line_end[k].x = j1; } //掩码为0,说明不是直线,但仍继续位移,直到间隙大于所设置的阈值为止 else if( ++gap > lineGap ) //间隙加1 break; } } //步骤5,由检测到的直线的两个端点粗略计算直线的长度 //当直线长度大于所设置的阈值时,good_line为1,否则为0 good_line = abs(line_end[1].x - line_end[0].x) >= lineLength || abs(line_end[1].y - line_end[0].y) >= lineLength; //再次搜索端点,目的是更新累加器矩阵和更新掩码矩阵,以备下一次循环使用 for( k = 0; k < 2; k++ ) { int x = x0, y = y0, dx = dx0, dy = dy0; if( k > 0 ) dx = -dx, dy = -dy; // walk along the line using fixed-point arithmetics, // stop at the image border or in case of too big gap for( ;; x += dx, y += dy ) { uchar* mdata; int i1, j1; if( xflag ) { j1 = x; i1 = y >> shift; } else { j1 = x >> shift; i1 = y; } mdata = mdata0 + i1*width + j1; // for each non-zero point: // update line end, // clear the mask element // reset the gap if( *mdata ) { //if语句的作用是清除那些已经判定是好的直线上的点对应的累加器的值,避免再次利用这些累加值 if( good_line ) //在第一次搜索中已经确定是好的直线 { //得到累加器矩阵地址指针 adata = (int*)accum.data; for( n = 0; n < numangle; n++, adata += numrho ) { r = cvRound( j1 * ttab[n*2] + i1 * ttab[n*2+1] ); r += (numrho - 1) / 2; adata[r]--; //相应的累加器减1 } } //搜索过的位置,不管是好的直线,还是坏的直线,掩码相应位置都清0,这样下次就不会再重复搜索这些位置了,从而达到减小计算边缘点的目的 *mdata = 0; } //如果已经到达了直线的端点,则退出循环 if( i1 == line_end[k].y && j1 == line_end[k].x ) break; } } //如果是好的直线 if( good_line ) { CvRect lr = { line_end[0].x, line_end[0].y, line_end[1].x, line_end[1].y }; //把两个端点压入序列中 cvSeqPush( lines, &lr ); //如果检测到的直线数量大于阈值,则退出该函数 if( lines->total >= linesMax ) return; } } } 6 霍夫圆变换原理及算法流程 6.1 经典霍夫圆变换 霍夫圆变换和霍夫线变换的原理类似。霍夫线变换是两个参数(r,θ),霍夫圆需要三个参数,圆心的x,y坐标和圆的半径,他的方程表达式为\((x-a)^{2} + (y-b)^{2} = c^{2}\),按照标准霍夫线变换思想,在xy平面,三个点在同一个圆上,则它们对应的空间曲面相交于一点(即点(a,b,c))。故我们如果知道一个边界上的点的数目,足够多,且这些点与之对应的空间曲面相交于一点。则这些点构成的边界,就接近一个圆形。上述描述的是标准霍夫圆变换的原理,由于三维空间的计算量大大增大的原因, 标准霍夫圆变化很难被应用到实际中。 具体可以参考下图: 6.2 霍夫梯度法的原理即算法流程(两个版本的解释) HoughCircles函数实现了圆形检测,它使用的算法也是改进的霍夫变换——2-1霍夫变换(21HT)。也就是把霍夫变换分为两个阶段,从而减小了霍夫空间的维数。第一阶段用于检测圆心,第二阶段从圆心推导出圆半径。检测圆心的原理是圆心是它所在圆周所有法线的交汇处,因此只要找到这个交点,即可确定圆心,该方法所用的霍夫空间与图像空间的性质相同,因此它仅仅是二维空间。检测圆半径的方法是从圆心到圆周上的任意一点的距离(即半径)是相同,只要确定一个阈值,只要相同距离的数量大于该阈值,我们就认为该距离就是该圆心所对应的圆半径,该方法只需要计算半径直方图,不使用霍夫空间。圆心和圆半径都得到了,那么通过公式1一个圆形就得到了。从上面的分析可以看出,2-1霍夫变换把标准霍夫变换的三维霍夫空间缩小为二维霍夫空间,因此无论在内存的使用上还是在运行效率上,2-1霍夫变换都远远优于标准霍夫变换。但该算法有一个不足之处就是由于圆半径的检测完全取决于圆心的检测,因此如果圆心检测出现偏差,那么圆半径的检测肯定也是错误的。 version 1: 2-1霍夫变换的具体步骤为: 1)首先对图像进行边缘检测,调用opencv自带的cvCanny()函数,将图像二值化,得到边缘图像。 2)对边缘图像上的每一个非零点。采用cvSobel()函数,计算x方向导数和y方向的导数,从而得到梯度。从边缘点,沿着梯度和梯度的反方向,对参数指定的min_radius到max_radium的每一个像素,在累加器中被累加。同时记下边缘图像中每一个非0点的位置。 3)从(二维)累加器中这些点中选择候选中心。这些中心都大于给定的阈值和其相邻的四个邻域点的累加值。 4)对于这些候选中心按照累加值降序排序,以便于最支持的像素的中心首次出现。 5)对于每一个中心,考虑到所有的非0像素(非0,梯度不为0),这些像素按照与其中心的距离排序,从最大支持的中心的最小距离算起,选择非零像素最支持的一条半径。 6)如果一个中心受到边缘图像非0像素的充分支持,并且到前期被选择的中心有足够的距离。则将圆心和半径压入到序列中,得以保留。 version 2: 第一阶段:检测圆心 1.1、对输入图像边缘检测; 1.2、计算图形的梯度,并确定圆周线,其中圆周的梯度就是它的法线; 1.3、在二维霍夫空间内,绘出所有图形的梯度直线,某坐标点上累加和的值越大,说明在该点上直线相交的次数越多,也就是越有可能是圆心;(备注:这只是直观的想法,实际源码并没有划线) 1.4、在霍夫空间的4邻域内进行非最大值抑制; 1.5、设定一个阈值,霍夫空间内累加和大于该阈值的点就对应于圆心。 第二阶段:检测圆半径 2.1、计算某一个圆心到所有圆周线的距离,这些距离中就有该圆心所对应的圆的半径的值,这些半径值当然是相等的,并且这些圆半径的数量要远远大于其他距离值相等的数量 2.2、设定两个阈值,定义为最大半径和最小半径,保留距离在这两个半径之间的值,这意味着我们检测的圆不能太大,也不能太小 2.3、对保留下来的距离进行排序 2.4、找到距离相同的那些值,并计算相同值的数量 2.5、设定一个阈值,只有相同值的数量大于该阈值,才认为该值是该圆心对应的圆半径 2.6、对每一个圆心,完成上面的2.1~2.5步骤,得到所有的圆半径 7 OpenCV圆变换函数 HoughCircles C++: void HoughCircles(InputArray image,OutputArray circles, int method, double dp, double minDist, double param1=100,double param2=100, int minRadius=0, int maxRadius=0 ) 第一个参数,InputArray类型的image,输入图像,即源图像,需为8位的灰度单通道图像。 第二个参数,InputArray类型的circles,经过调用HoughCircles函数后此参数存储了检测到的圆的输出矢量,每个矢量由包含了3个元素的浮点矢量(x, y, radius)表示。 第三个参数,int类型的method,即使用的检测方法,目前OpenCV中就霍夫梯度法一种可以使用,它的标识符为CV_HOUGH_GRADIENT,在此参数处填这个标识符即可。 第四个参数,double类型的dp,用来检测圆心的累加器图像的分辨率于输入图像之比的倒数,且此参数允许创建一个比输入图像分辨率低的累加器。上述文字不好理解的话,来看例子吧。例如,如果dp= 1时,累加器和输入图像具有相同的分辨率。如果dp=2,累加器便有输入图像一半那么大的宽度和高度。 第五个参数,double类型的minDist,为霍夫变换检测到的圆的圆心之间的最小距离,即让我们的算法能明显区分的两个不同圆之间的最小距离。这个参数如果太小的话,多个相邻的圆可能被错误地检测成了一个重合的圆。反之,这个参数设置太大的话,某些圆就不能被检测出来了。 第六个参数,double类型的param1,有默认值100。它是第三个参数method设置的检测方法的对应的参数。对当前唯一的方法霍夫梯度法CV_HOUGH_GRADIENT,它表示传递给canny边缘检测算子的高阈值,而低阈值为高阈值的一半。 第七个参数,double类型的param2,也有默认值100。它是第三个参数method设置的检测方法的对应的参数。对当前唯一的方法霍夫梯度法CV_HOUGH_GRADIENT,它表示在检测阶段圆心的累加器阈值。它越小的话,就可以检测到更多根本不存在的圆,而它越大的话,能通过检测的圆就更加接近完美的圆形了。 第八个参数,int类型的minRadius,有默认值0,表示圆半径的最小值。 第九个参数,int类型的maxRadius,也有默认值0,表示圆半径的最大值。 8 源码分析 有两个版本的注释,一样的,结合来看 其中几个点: 霍夫空间是用于统计坐标点,分辨率没有必要与原图像一致,所以用dp来调整霍夫空间的大小,从而提高运算速度。而ONE的作用是为了减小运算过程中的累积误差,提高精度,如:1/3=0.333333,如果保留小数点后5位,则为0.33333,但如果向左位移3位,则为333.33333,这个数的精度要比前一个高,只要我们把所有的数都向左位移3位,最终的结果再向右位移3位,最后的数值精度会提高不少的。基本思想就是这个。 8.1 version1:论文中的 /****************************************************************************************\ * Circle Detection * \****************************************************************************************/ /*------------------------------------霍夫梯度法------------------------------------------*/ static void icvHoughCirclesGradient( CvMat* img, float dp, float min_dist, int min_radius, int max_radius, int canny_threshold, int acc_threshold, CvSeq* circles, int circles_max ) { const int SHIFT = 10, ONE = 1 << SHIFT, R_THRESH = 30; //One=1024,1左移10位2*10,R_THRESH是起始值,赋给max_count,后续会被覆盖。 cv::Ptr cv::Ptr std::vector cv::Ptr int x, y, i, j, k, center_count, nz_count;//center_count为圆心数,nz_count为非零数 float min_radius2 = (float)min_radius*min_radius;//最小半径的平方 float max_radius2 = (float)max_radius*max_radius;//最大半径的平方 int rows, cols, arows,acols;//rows,cols边缘图像的行数和列数,arows,acols是累加器图像的行数和列数 int astep, *adata;//adata指向累加器数据域的首地址,用位置作为下标,astep为累加器每行的大小,以字节为单位 float* ddata;//ddata即dist_data,距离数据 CvSeq *nz, *centers;//nz为非0,即边界,centers为存放的候选中心的位置。 float idp, dr;//idp即inv_dp,dp的倒数 CvSeqReader reader;//顺序读取序列中的每个值 edges = cvCreateMat( img->rows, img->cols, CV_8UC1 );//边缘图像 cvCanny( img, edges, MAX(canny_threshold/2,1), canny_threshold, 3 );//调用canny,变为二值图像,0和非0即0和255 dx = cvCreateMat( img->rows, img->cols, CV_16SC1 );//16位单通道图像,用来存储二值边缘图像的x方向的一阶导数 dy = cvCreateMat( img->rows, img->cols, CV_16SC1 );//y方向的 cvSobel( img, dx, 1, 0, 3 );//计算x方向的一阶导数 cvSobel( img, dy, 0, 1, 3 );//计算y方向的一阶导数 if( dp < 1.f )//控制dp不能比1小 dp = 1.f; idp = 1.f/dp; accum = cvCreateMat( cvCeil(img->rows*idp)+2, cvCeil(img->cols*idp)+2, CV_32SC1 );//cvCeil返回不小于参数的最小整数。32为单通道 cvZero(accum);//初始化累加器为0 storage = cvCreateMemStorage();//创建内存存储器,使用默认参数0.默认大小为64KB nz = cvCreateSeq( CV_32SC2, sizeof(CvSeq), sizeof(CvPoint), storage );//创建序列,用来存放非0点 centers = cvCreateSeq( CV_32SC1, sizeof(CvSeq), sizeof(int), storage );//用来存放圆心 rows = img->rows; cols = img->cols; arows = accum->rows - 2; acols = accum->cols - 2; adata = accum->data.i;//cvMat对象的union对象的i成员成员 //step是矩阵中行的长度,单位为字节。我们使用到的矩阵是accum它的深度是CV_32SC1即32位的int 型。 //如果我们知道一个指针如int* p;指向数组中的一个元素, 则可以通过p+accum->step/adata[0]来使指针移动到p指针所指元素的,正对的下一行元素 astep = accum->step/sizeof(adata[0]); for( y = 0; y < rows; y++ ) { const uchar* edges_row = edges->data.ptr + y*edges->step; //边界存储的矩阵的每一行的指向行首的指针。 const short* dx_row = (const short*)(dx->data.ptr + y*dx->step);//存储 x方向sobel一阶导数的矩阵的每一行的指向第一个元素的指针 const short* dy_row = (const short*)(dy->data.ptr + y*dy->step);//y //遍历边缘的二值图像和偏导数的图像 for( x = 0; x < cols; x++ ) { float vx, vy; int sx, sy, x0, y0, x1, y1, r, k; CvPoint pt; vx = dx_row[x];//访问每一行的元素 vy = dy_row[x]; if( !edges_row[x] || (vx == 0 && vy == 0) )//如果在边缘图像(存储边缘的二值图像)某一点如A(x0,y0)==0则对一下点进行操作。vx和vy同时为0,则下一个 continue; float mag = sqrt(vx*vx+vy*vy);//求梯度图像 assert( mag >= 1 );//如果mag为0,说明没有边缘点,则stop。这里用了assert宏定义 sx = cvRound((vx*idp)*ONE/mag);// vx为该点的水平梯度(梯度幅值已经归一化);ONE为为了用整数运算代替浮点数引入的一个因子,为2^10 sy = cvRound((vy*idp)*ONE/mag); x0 = cvRound((x*idp)*ONE); y0 = cvRound((y*idp)*ONE); for( k = 0; k < 2; k++ )//k=0在梯度方向,k=1在梯度反方向对累加器累加。这里之所以要反向,因为对于一个圆上一个点,从这个点沿着斜率的方向的,最小半径到最大半径。在圆的另一边与其相对应的点,有对应的效果。 { x1 = x0 + min_radius * sx; y1 = y0 + min_radius * sy; for( r = min_radius; r <= max_radius; x1 += sx, y1 += sy, r++ )//x1=x1+sx即,x1=x0+min_radius*sx+sx=x0+(min_radius+1)*sx求得下一个点。sx为斜率 { int x2 = x1 >> SHIFT, y2 = y1 >> SHIFT; //变回真实的坐标 if( (unsigned)x2 >= (unsigned)acols || //如果x2大于累加器的行 (unsigned)y2 >= (unsigned)arows ) break; adata[y2*astep + x2]++;//由于c语言是按行存储的。即等价于对accum数组进行了操作。 } sx = -sx; sy = -sy; } pt.x = x; pt.y = y; cvSeqPush( nz, &pt );//把非零边缘并且梯度不为0的点压入到堆栈 } } nz_count = nz->total; if( !nz_count )//如果nz_count==0则返回 return; for( y = 1; y < arows - 1; y++ ) //这里是从1到arows-1,因为如果是圆的话,那么圆的半径至少为1,即圆心至少在内层里面 { for( x = 1; x < acols - 1; x++ ) { int base = y*(acols+2) + x;//计算位置,在accum图像中 if( adata[base] > acc_threshold && adata[base] > adata[base-1] && adata[base] > adata[base+1] && adata[base] > adata[base-acols-2] && adata[base] > adata[base+acols+2] ) cvSeqPush(centers, &base);//候选中心点位置压入到堆栈。其候选中心点累加数大于阈值,其大于四个邻域 } } center_count = centers->total; if( !center_count ) //如果没有符合条件的圆心,则返回到函数。 return; sort_buf.resize( MAX(center_count,nz_count) );//重新分配容器的大小,取候选圆心的个数和非零边界的个数的最大值。因为后面两个均用到排序。 cvCvtSeqToArray( centers, &sort_buf[0] ); //把序列转换成数组,即把序列centers中的数据放入到sort_buf的容器中。 icvHoughSortDescent32s( &sort_buf[0], center_count, adata );//快速排序,根据sort_buf中的值作为下标,依照adata中对应的值进行排序,将累加值大的下标排到前面 cvClearSeq( centers );//清空序列 cvSeqPushMulti( centers, &sort_buf[0], center_count );//重新将中心的下标存入centers dist_buf = cvCreateMat( 1, nz_count, CV_32FC1 );//创建一个32为浮点型的一个行向量 ddata = dist_buf->data.fl;//使ddata执行这个行向量的首地址 dr = dp; min_dist = MAX( min_dist, dp );//如果输入的最小距离小于dp,则设在为dp min_dist *= min_dist; for( i = 0; i < centers->total; i++ ) //对于每一个中心点 { int ofs = *(int*)cvGetSeqElem( centers, i );//获取排序的中心位置,adata值最大的元素,排在首位 ,offset偏移位置 y = ofs/(acols+2) - 1;//这里因为edge图像比accum图像小两个边。 x = ofs - (y+1)*(acols+2) - 1;//求得y坐标 float cx = (float)(x*dp), cy = (float)(y*dp); float start_dist, dist_sum; float r_best = 0, c[3]; int max_count = R_THRESH; for( j = 0; j < circles->total; j++ )//中存储已经找到的圆;若当前候选圆心与其中的一个圆心距离 { float* c = (float*)cvGetSeqElem( circles, j );//获取序列中的元素。 if( (c[0] - cx)*(c[0] - cx) + (c[1] - cy)*(c[1] - cy) < min_dist ) break; } if( j < circles->total )//当前候选圆心与任意已检测的圆心距离不小于min_dist时,才有j==circles->total continue; cvStartReadSeq( nz, &reader ); for( j = k = 0; j < nz_count; j++ )//每个候选圆心,对于所有的点 { CvPoint pt; float _dx, _dy, _r2; CV_READ_SEQ_ELEM( pt, reader ); _dx = cx - pt.x; _dy = cy - pt.y; //中心点到边界的距离 _r2 = _dx*_dx + _dy*_dy; if(min_radius2 <= _r2 && _r2 <= max_radius2 ) { ddata[k] = _r2; //把满足的半径的平方存起来 sort_buf[k] = k;//sort_buf同上,但是这里的sort_buf的下标值和元素值是相同的,重新利用 k++;//k和j是两个游标 } } int nz_count1 = k, start_idx = nz_count1 - 1; if( nz_count1 == 0 ) continue; //如果一个候选中心到(非零边界且梯度>0)确定的点的距离中,没有满足条件的,则从下一个中心点开始。 dist_buf->cols = nz_count1;//用来存放真是的满足条件的非零元素(三个约束:非零点,梯度不为0,到圆心的距离在min_radius和max_radius中间) cvPow( dist_buf, dist_buf, 0.5 );//对dist_buf中的元素开根号.求得半径 icvHoughSortDescent32s( &sort_buf[0], nz_count1, (int*)ddata );////对与圆心的距离按降序排列,索引值在sort_buf中 dist_sum = start_dist = ddata[sort_buf[nz_count1-1]];//dist距离,选取半径最小的作为起始值 //下边for循环里面是一个算法。它定义了两个游标(指针)start_idx和j,j是外层循环的控制变量。而start_idx为控制当两个相邻的数组ddata的数据发生变化时,即d-start_dist>dr时,的步进。 for( j = nz_count1 - 2; j >= 0; j-- )//从小到大。选出半径支持点数最多的半径 { float d = ddata[sort_buf[j]]; if( d > max_radius )//如果求得的候选圆点到边界的距离大于参数max_radius,则停止,因为d是第一个出现的最小的(按照从大到小的顺序排列的) break; if( d - start_dist > dr )//如果当前的距离减去最小的>dr(==dp) { float r_cur = ddata[sort_buf[(j + start_idx)/2]];//当前半径设为符合该半径的中值,j和start_idx相当于两个游标 if( (start_idx - j)*r_best >= max_count*r_cur || //如果数目相等时,它会找半径较小的那个。这里是判断支持度的算法 (r_best < FLT_EPSILON && start_idx - j >= max_count) ) //程序这个部分告诉我们,无法找到同心圆,它会被外层最大,支持度最多(支持的点最多)所覆盖。 { r_best = r_cur;//如果 符合当前半径的点数(start_idx - j)/ 当前半径>= 符合之前最优半径的点数/之前的最优半径 || 还没有最优半径时,且点数>30时;其实直接把r_best初始值置为1即可省去第二个条件 max_count = start_idx - j;//maxcount变为符合当前半径的点数,更新max_count值,后续的支持度大的半径将会覆盖前面的值。 } start_dist = d; start_idx = j; dist_sum = 0;//如果距离改变较大,则重置distsum为0,再在下面的式子中置为当前值 } dist_sum += d;//如果距离改变较小,则加上当前值(dist_sum)在这里好像没有用处。 } if( max_count > R_THRESH )//符合条件的圆周点大于阈值30,则将圆心、半径压栈 { c[0] = cx; c[1] = cy; c[2] = (float)r_best; cvSeqPush( circles, c ); if( circles->total > circles_max )//circles_max是个很大的数,其值为INT_MAX return; } } } CV_IMPL CvSeq* cvHoughCircles1( CvArr* src_image, void* circle_storage, int method, double dp, double min_dist, double param1, double param2, int min_radius, int max_radius ) { CvSeq* result = 0; CvMat stub, *img = (CvMat*)src_image; CvMat* mat = 0; CvSeq* circles = 0; CvSeq circles_header; CvSeqBlock circles_block; int circles_max = INT_MAX; int canny_threshold = cvRound(param1);//cvRound返回和参数最接近的整数值,对一个double类型进行四舍五入 int acc_threshold = cvRound(param2); img = cvGetMat( img, &stub );//将img转化成为CvMat对象 if( !CV_IS_MASK_ARR(img)) //图像必须为8位,单通道图像 CV_Error( CV_StsBadArg, "The source image must be 8-bit, single-channel" ); if( !circle_storage ) CV_Error( CV_StsNullPtr, "NULL destination" ); if( dp <= 0 || min_dist <= 0 || canny_threshold <= 0 || acc_threshold <= 0 ) CV_Error( CV_StsOutOfRange, "dp, min_dist, canny_threshold and acc_threshold must be all positive numbers" ); min_radius = MAX( min_radius, 0 ); if( max_radius <= 0 )//用来控制当使用默认参数max_radius=0的时候 max_radius = MAX( img->rows, img->cols ); else if( max_radius <= min_radius ) max_radius = min_radius + 2; if( CV_IS_STORAGE( circle_storage ))//如果传入的是内存存储器 { circles = cvCreateSeq( CV_32FC3, sizeof(CvSeq), sizeof(float)*3, (CvMemStorage*)circle_storage ); } else if( CV_IS_MAT( circle_storage ))//如果传入的参数时数组 { mat = (CvMat*)circle_storage; //数组应该是CV_32FC3类型的单列数组。 if( !CV_IS_MAT_CONT( mat->type ) || (mat->rows != 1 && mat->cols != 1) ||//连续,单列,CV_32FC3类型 CV_MAT_TYPE(mat->type) != CV_32FC3 ) CV_Error( CV_StsBadArg, "The destination matrix should be continuous and have a single row or a single column" ); //将数组转换为序列 circles = cvMakeSeqHeaderForArray( CV_32FC3, sizeof(CvSeq), sizeof(float)*3, mat->data.ptr, mat->rows + mat->cols - 1, &circles_header, &circles_block );//由于是单列,故elem_size为mat->rows+mat->cols-1 circles_max = circles->total; cvClearSeq( circles );//清空序列的内容(如果传入的有数据的话) } else CV_Error( CV_StsBadArg, "Destination is not CvMemStorage* nor CvMat*" ); switch( method ) { case CV_HOUGH_GRADIENT: icvHoughCirclesGradient( img, (float)dp, (float)min_dist, min_radius, max_radius, canny_threshold, acc_threshold, circles, circles_max ); break; default: CV_Error( CV_StsBadArg, "Unrecognized method id" ); } if( mat )//给定一个指向圆存储的数组指针值,则返回0,即NULL { if( mat->cols > mat->rows )//因为不知道传入的是列向量还是行向量。 mat->cols = circles->total; else mat->rows = circles->total; } else//如果是传入的是内存存储器,则返回一个指向一个序列的指针。 result = circles; return result; } 8.2 version2:(赵老师) static void icvHoughCirclesGradient( CvMat* img, float dp, float min_dist, int min_radius, int max_radius, int canny_threshold, int acc_threshold, CvSeq* circles, int circles_max ) { //为了提高运算精度,定义一个数值的位移量 const int SHIFT = 10, ONE = 1 << SHIFT; //定义水平梯度和垂直梯度矩阵的地址指针 cv::Ptr //定义边缘图像、累加器矩阵和半径距离矩阵的地址指针 cv::Ptr //定义排序向量 std::vector cv::Ptr int x, y, i, j, k, center_count, nz_count; //事先计算好最小半径和最大半径的平方 float min_radius2 = (float)min_radius*min_radius; float max_radius2 = (float)max_radius*max_radius; int rows, cols, arows, acols; int astep, *adata; float* ddata; //nz表示圆周序列,centers表示圆心序列 CvSeq *nz, *centers; float idp, dr; CvSeqReader reader; //创建一个边缘图像矩阵 edges = cvCreateMat( img->rows, img->cols, CV_8UC1 ); //第一阶段 //步骤1.1,用canny边缘检测算法得到输入图像的边缘图像 cvCanny( img, edges, MAX(canny_threshold/2,1), canny_threshold, 3 ); //创建输入图像的水平梯度图像和垂直梯度图像 dx = cvCreateMat( img->rows, img->cols, CV_16SC1 ); dy = cvCreateMat( img->rows, img->cols, CV_16SC1 ); //步骤1.2,用Sobel算子法计算水平梯度和垂直梯度 cvSobel( img, dx, 1, 0, 3 ); cvSobel( img, dy, 0, 1, 3 ); /确保累加器矩阵的分辨率不小于1 if( dp < 1.f ) dp = 1.f; //分辨率的倒数 idp = 1.f/dp; //根据分辨率,创建累加器矩阵 accum = cvCreateMat( cvCeil(img->rows*idp)+2, cvCeil(img->cols*idp)+2, CV_32SC1 ); //初始化累加器为0 cvZero(accum); //创建两个序列, storage = cvCreateMemStorage(); nz = cvCreateSeq( CV_32SC2, sizeof(CvSeq), sizeof(CvPoint), storage ); centers = cvCreateSeq( CV_32SC1, sizeof(CvSeq), sizeof(int), storage ); rows = img->rows; //图像的高 cols = img->cols; //图像的宽 arows = accum->rows - 2; //累加器的高 acols = accum->cols - 2; //累加器的宽 adata = accum->data.i; //累加器的地址指针 astep = accum->step/sizeof(adata[0]); /累加器的步长 // Accumulate circle evidence for each edge pixel //步骤1.3,对边缘图像计算累加和 for( y = 0; y < rows; y++ ) { //提取出边缘图像、水平梯度图像和垂直梯度图像的每行的首地址 const uchar* edges_row = edges->data.ptr + y*edges->step; const short* dx_row = (const short*)(dx->data.ptr + y*dx->step); const short* dy_row = (const short*)(dy->data.ptr + y*dy->step); for( x = 0; x < cols; x++ ) { float vx, vy; int sx, sy, x0, y0, x1, y1, r; CvPoint pt; //当前的水平梯度值和垂直梯度值 vx = dx_row[x]; vy = dy_row[x]; //如果当前的像素不是边缘点,或者水平梯度值和垂直梯度值都为0,则继续循环。因为如果满足上面条件,该点一定不是圆周上的点 if( !edges_row[x] || (vx == 0 && vy == 0) ) continue; //计算当前点的梯度值 float mag = sqrt(vx*vx+vy*vy); assert( mag >= 1 ); //定义水平和垂直的位移量 sx = cvRound((vx*idp)*ONE/mag); sy = cvRound((vy*idp)*ONE/mag); //把当前点的坐标定位到累加器的位置上 x0 = cvRound((x*idp)*ONE); y0 = cvRound((y*idp)*ONE); // Step from min_radius to max_radius in both directions of the gradient //在梯度的两个方向上进行位移,并对累加器进行投票累计 for(int k1 = 0; k1 < 2; k1++ ) { //初始一个位移的启动 //位移量乘以最小半径,从而保证了所检测的圆的半径一定是大于最小半径 x1 = x0 + min_radius * sx; y1 = y0 + min_radius * sy; //在梯度的方向上位移 // r <= max_radius保证了所检测的圆的半径一定是小于最大半径 for( r = min_radius; r <= max_radius; x1 += sx, y1 += sy, r++ ) { int x2 = x1 >> SHIFT, y2 = y1 >> SHIFT; //如果位移后的点超过了累加器矩阵的范围,则退出 if( (unsigned)x2 >= (unsigned)acols || (unsigned)y2 >= (unsigned)arows ) break; //在累加器的相应位置上加1 adata[y2*astep + x2]++; } //把位移量设置为反方向 sx = -sx; sy = -sy; } //把输入图像中的当前点(即圆周上的点)的坐标压入序列圆周序列nz中 pt.x = x; pt.y = y; cvSeqPush( nz, &pt ); } } //计算圆周点的总数 nz_count = nz->total; //如果总数为0,说明没有检测到圆,则退出该函数 if( !nz_count ) return; //Find possible circle centers //步骤1.4和1.5,遍历整个累加器矩阵,找到可能的圆心 for( y = 1; y < arows - 1; y++ ) { for( x = 1; x < acols - 1; x++ ) { int base = y*(acols+2) + x; //如果当前的值大于阈值,并在4邻域内它是最大值,则该点被认为是圆心 if( adata[base] > acc_threshold && adata[base] > adata[base-1] && adata[base] > adata[base+1] && adata[base] > adata[base-acols-2] && adata[base] > adata[base+acols+2] ) //把当前点的地址压入圆心序列centers中 cvSeqPush(centers, &base); } } //计算圆心的总数 center_count = centers->total; //如果总数为0,说明没有检测到圆,则退出该函数 if( !center_count ) return; //定义排序向量的大小 sort_buf.resize( MAX(center_count,nz_count) ); //把圆心序列放入排序向量中 cvCvtSeqToArray( centers, &sort_buf[0] ); //对圆心按照由大到小的顺序进行排序 //它的原理是经过icvHoughSortDescent32s函数后,以sort_buf中元素作为adata数组下标,adata中的元素降序排列,即adata[sort_buf[0]]是adata所有元素中最大的,adata[sort_buf[center_count-1]]是所有元素中最小的 icvHoughSortDescent32s( &sort_buf[0], center_count, adata ); //清空圆心序列 cvClearSeq( centers ); //把排好序的圆心重新放入圆心序列中 cvSeqPushMulti( centers, &sort_buf[0], center_count ); //创建半径距离矩阵 dist_buf = cvCreateMat( 1, nz_count, CV_32FC1 ); //定义地址指针 ddata = dist_buf->data.fl; dr = dp; //定义圆半径的距离分辨率 //重新定义圆心之间的最小距离 min_dist = MAX( min_dist, dp ); //最小距离的平方 min_dist *= min_dist; // For each found possible center // Estimate radius and check support //按照由大到小的顺序遍历整个圆心序列 for( i = 0; i < centers->total; i++ ) { //提取出圆心,得到该点在累加器矩阵中的偏移量 int ofs = *(int*)cvGetSeqElem( centers, i ); //得到圆心在累加器中的坐标位置 y = ofs/(acols+2); x = ofs - (y)*(acols+2); //Calculate circle's center in pixels //计算圆心在输入图像中的坐标位置 float cx = (float)((x + 0.5f)*dp), cy = (float)(( y + 0.5f )*dp); float start_dist, dist_sum; float r_best = 0; int max_count = 0; // Check distance with previously detected circles //判断当前的圆心与之前确定作为输出的圆心是否为同一个圆心 for( j = 0; j < circles->total; j++ ) { //从序列中提取出圆心 float* c = (float*)cvGetSeqElem( circles, j ); //计算当前圆心与提取出的圆心之间的距离,如果两者距离小于所设的阈值,则认为两个圆心是同一个圆心,退出循环 if( (c[0] - cx)*(c[0] - cx) + (c[1] - cy)*(c[1] - cy) < min_dist ) break; } //如果j < circles->total,说明当前的圆心已被认为与之前确定作为输出的圆心是同一个圆心,则抛弃该圆心,返回上面的for循环 if( j < circles->total ) continue; // Estimate best radius //第二阶段 //开始读取圆周序列nz cvStartReadSeq( nz, &reader ); for( j = k = 0; j < nz_count; j++ ) { CvPoint pt; float _dx, _dy, _r2; CV_READ_SEQ_ELEM( pt, reader ); _dx = cx - pt.x; _dy = cy - pt.y; //步骤2.1,计算圆周上的点与当前圆心的距离,即半径 _r2 = _dx*_dx + _dy*_dy; //步骤2.2,如果半径在所设置的最大半径和最小半径之间 if(min_radius2 <= _r2 && _r2 <= max_radius2 ) { //把半径存入dist_buf内 ddata[k] = _r2; sort_buf[k] = k; k++; } } //k表示一共有多少个圆周上的点 int nz_count1 = k, start_idx = nz_count1 - 1; //nz_count1等于0也就是k等于0,说明当前的圆心没有所对应的圆,意味着当前圆心不是真正的圆心,所以抛弃该圆心,返回上面的for循环 if( nz_count1 == 0 ) continue; dist_buf->cols = nz_count1; //得到圆周上点的个数 cvPow( dist_buf, dist_buf, 0.5 ); //求平方根,得到真正的圆半径 //步骤2.3,对圆半径进行排序 icvHoughSortDescent32s( &sort_buf[0], nz_count1, (int*)ddata ); dist_sum = start_dist = ddata[sort_buf[nz_count1-1]]; //步骤2.4 for( j = nz_count1 - 2; j >= 0; j-- ) { float d = ddata[sort_buf[j]]; if( d > max_radius ) break; //d表示当前半径值,start_dist表示上一次通过下面if语句更新后的半径值,dr表示半径距离分辨率,如果这两个半径距离之差大于距离分辨率,说明这两个半径一定不属于同一个圆,而两次满足if语句条件之间的那些半径值可以认为是相等的,即是属于同一个圆 if( d - start_dist > dr ) { //start_idx表示上一次进入if语句时更新的半径距离排序的序号 // start_idx – j表示当前得到的相同半径距离的数量 //(j + start_idx)/2表示j和start_idx中间的数 //取中间的数所对应的半径值作为当前半径值r_cur,也就是取那些半径值相同的值 float r_cur = ddata[sort_buf[(j + start_idx)/2]]; //如果当前得到的半径相同的数量大于最大值max_count,则进入if语句 if( (start_idx - j)*r_best >= max_count*r_cur || (r_best < FLT_EPSILON && start_idx - j >= max_count) ) { r_best = r_cur; //把当前半径值作为最佳半径值 max_count = start_idx - j; //更新最大值 } //更新半径距离和序号 start_dist = d; start_idx = j; dist_sum = 0; } dist_sum += d; } // Check if the circle has enough support //步骤2.5,最终确定输出 //如果相同半径的数量大于所设阈值 if( max_count > acc_threshold ) { float c[3]; c[0] = cx; //圆心的横坐标 c[1] = cy; //圆心的纵坐标 c[2] = (float)r_best; //所对应的圆的半径 cvSeqPush( circles, c ); //压入序列circles内 //如果得到的圆大于阈值,则退出该函数 if( circles->total > circles_max ) return; } } } 9 参考文章 https://blog.csdn.net/qq_37059483/article/details/77916655 https://blog.csdn.net/m0_37264397/article/details/72729423 https://blog.csdn.net/zhaocj/article/details/50454847 https://blog.csdn.net/shanchuan2012/article/details/74010561 http://www.cnblogs.com/AndyJee/p/3805594.html https://blog.csdn.net/cy513/article/details/4269340 https://blog.csdn.net/poem_qianmo/article/details/26977557 http://homepages.inf.ed.ac.uk/rbf/HIPR2/hough.htm https://blog.csdn.net/m0_37264397/article/details/72729423 https://www.cnblogs.com/AndyJee/p/3805594.html ---恢复内容结束--- @目录2 标准霍夫线变换原理2.1 霍夫变换直线的方程2.2 霍夫空间2.3 检测直线的方法2.4 一个例子3 霍夫线变换的算法流程3.1 标准霍夫线变换算法流程3.2 统计概率霍夫变换算法流程4 OpenCV中的霍夫变换函数4.1标准霍夫变换HoughLines()函数4.2 统计概率霍夫变换(HoughLinesP)5 源码分析5.1 HoughLines()源码分析5.2 HoughLinesP源码分析6 霍夫圆变换原理及算法流程6.1 经典霍夫圆变换6.2 霍夫梯度法的原理即算法流程(两个版本的解释)7 OpenCV圆变换函数 HoughCircles8 源码分析8.1 version1:论文中的8.2 version2:(赵老师)9 参考文章1 简述2 标准霍夫线变换原理2.1 霍夫变换直线的方程2.2 霍夫空间2.3 检测直线的方法2.4 一个例子3 霍夫线变换的算法流程3.1 标准霍夫线变换算法流程3.2 统计概率霍夫变换算法流程4 OpenCV中的霍夫变换函数4.1标准霍夫变换HoughLines()函数4.2 统计概率霍夫变换(HoughLinesP)5 源码分析5.1 HoughLines()源码分析5.2 HoughLinesP源码分析6 霍夫圆变换原理及算法流程6.1 经典霍夫圆变换6.2 霍夫梯度法的原理即算法流程(两个版本的解释)7 OpenCV圆变换函数 HoughCircles8 源码分析8.1 version1:论文中的8.2 version2:(赵老师)9 参考文章 1 简述 霍夫变换是一个经典的特征提取技术,本文主要说的是霍夫线/圆变换,即从图像中获取直线与圆,同时需要对图像进行二值化操作,效果如下。 霍夫变换目的通过投票程序在特定类型的形状内找到对象的不完美示例,这个投票程序是在一个参数空间中进行的,在这个参数空间中,候选对象被当作所谓的累加器空间中的局部最大值来获得,所述累加器空间由用于计算霍夫变换的算法明确的构建,霍夫变换不仅能够识别出图像中有无需要检测的图形,而且能够定位到该图像(包括位置、角度等),有标准霍夫变换,多尺度霍夫变换,统计概率霍夫变换3种较为经典的方法,主要优点是能容忍特征边界描述中的间隙,并且相对不受图像噪声的影响。 2 标准霍夫线变换原理 2.1 霍夫变换直线的方程 直线的方程形式有截距式,斜截式,一般式,点斜式等,但是这些形式都有“奇异”情况,其中一个截距为0,斜率为0, c=0(通常把c除到等式左面,减少一个参数的搜索),另外某些形式的参数空间不是闭的,比如斜截式的斜率k,取值范围从0到无穷大,给量化搜索带来了困难。所以在霍夫线变换中采用了如下方程的形式: \[p = xcos\theta + ysin\theta \] 其中\(p\)与\(\theta\)都是极坐标下点的极径与极角(也可以理解\(p\)是原点离直线最近的距离),但并不是极坐标方程,因为还在笛卡尔坐标下表示,两个参数的意义如下图: 这个方程的巧妙之处是角度与距离这两个参数都是有界的,而且没有奇异的情况,因此可以在参数空间中进行搜索。同时,直线霍夫变换有2个参数通过这一个等式相关联,所以程序在投票阶段只需要遍历其中一个,通过等式获取另一个参数从而进行投票与搜索峰值。 2.2 霍夫空间 对于直线来说,可以将图像的每一条直线与一对参数\((p, \theta)\)相关联,这个参数\((p, \theta)\)平面有时被称为霍夫空间,用于二维直线的集合,因此,对于某一指定的点,不同的\((p, \theta)\)代表了不同的直线,我们把\((p, \theta)\)之间的关系通过图像表示出来——固定一个点(3,4),角度取[0,2\(\pi\)]时,\(r\)的范围取值情况: 会发现曲线的形状类似一条正弦曲线,通常\(p\)越大,正弦曲线的振幅越大,反而就会越小。 2.3 检测直线的方法 可以得到一个结论,给定平面中的单个点,那么通过该点的所有直线的集合对应于(r,θ)平面中的正弦曲线,这对于该点是独特的。一组两个或更多点形成一条直线将产生在该线的(r,θ)处交叉的一条或多条正弦曲线。因此,检测共线点的问题可以转化为找到并发曲线的问题。 具体的,通过将霍夫参数空间量化为有限间隔或累加器单元来实现变换。随着算法的运行,每个算法都把\((x_{i}, y_{i})\)转换为一个离散化的 \((r,θ)\)曲线,并且沿着这条曲线的累加器单元被递增。累加器阵列中产生的峰值表示图像中存在相应的直线的有力证据。 换句话说,将每个交点看成一次投票,也就是说\(A(r,θ)=A(r,θ)+1\),所有点都如此进行计算后,可以设置一个阈值,投票大于这个阈值的可以认为是找到的直线。 2.4 一个例子 举一个具体的例子,来体现霍夫变换的流程同时更深的理解一下该算法(此例子摘取某博客,下文会给出所有参考博客的链接) 霍夫变换可用于识别最适合一组给定边缘点的曲线的参数。该边缘描述通常从诸如Roberts Cross,Sobel或 Canny边缘检测器的特征检测算子获得,并且可能是嘈杂的,即其可能包含对应于单个整体特征的多个边缘片段。此外,由于边缘检测器的输出仅限定图像中的特征的位置,所以霍夫变换进一步是确定两个特征是什么(即检测其具有参数(或其他)的特征描述)以及 它们有多少个存在于图像中。 为了详细说明霍夫变换,我们从两个闭合矩形的简单图像开始。 使用 Canny边缘检测器可产生一组边界描述的这个部分,如下图: 这里我们看到了图像中的整体边界,但是这个结果并没有告诉我们边界描述中的特征的身份(和数量)。在这种情况下,我们可以使用Hough(线检测)变换来检测该图像的八个单独的直线段,从而确定对象的真实几何结构。 如果我们使用这些边缘/边界点作为Hough变换的输入,每一个点通过遍历不同的\((r, \theta)\)都会在笛卡尔空间中生成一条曲线,当被视为强度图像时, 累加器阵列看起来像如下所示: 可以利用直方图均衡技术使得图像可以让我们看到包含在低强度像素值中的信息模式,如下图: 注意,虽然r和θ是概念上的极坐标,但是累加器空间以横坐标θ和纵坐标r的矩形绘制 。请注意,累加器空间环绕图像的垂直边缘,因此实际上只有8个实际峰值。 由梯度图像中的共线点生成的曲线(r,θ) 在霍夫变换空间中的峰中相交。这些交点表征原始图像的直线段。有许多方法可用于从累加器阵列中提取这些亮点或局部最大值。例如,一个简单的方法涉及阈值处理,然后 对累加器阵列图像中孤立的亮点集群进行一些细化处理。这里我们使用相对阈值来提取(r,θ) ,对应于原始图像中的每条直线边缘的点。(换句话说,我们只采用累加器数组中的那些局部最大值,其值等于或大于全局最大值的某个固定百分比。) 从Hough变换空间(即,反霍夫变换)映射回笛卡尔空间产生一组图像主题的线描述。通过将该图像叠加在原始的反转版本上,我们可以确认霍夫变换找到两个矩形的8个真实边的结果,并且因此展示出了遮挡场景的基础几何形状。 请注意,在这个简单的例子中,检测到的和原始图像线的对齐精度显然不完美,这取决于累加器阵列的量化。(还要注意许多图像边缘有几条检测线,这是因为有几个附近的霍夫空间峰值具有相似的线参数值,存在控制这种效应的技术,但这里没有用来说明标准霍夫变换) 还要注意,由霍夫变换产生的线条的长度是无限的。如果我们希望识别产生变换参数的实际线段,则需要进一步的图像分析以便查看这些无限长线的哪些部分实际上具有点。 为了说明Hough技术对噪声的鲁棒性,Canny边缘描述已被破坏1%(由椒盐噪声引起), 在Hough变换之前,如图12所示。 霍夫空间如下图所示: 将这个结果反霍夫变换(相对阈值设置为40%,并将它覆盖在原来的结果上) 可以通过变换图像来研究Hough变换对特征边界中的间隙的敏感性,如下图: 然后我们再将其变换到霍夫变换空间,如下图 然后使用40%的相对阈值去对图像反霍夫变换(同样也是叠加在原图上) 在这种情况下,因为累加器空间没有接收到前面例子中的条目数量,只能找到7个峰值,但这些都是结构相关的线。 3 霍夫线变换的算法流程 3.1 标准霍夫线变换算法流程 读取原始图像,并转换成灰度图,利用阈值分割或者边缘检测算子转换成二值化边缘图像 初始化霍夫空间, 令所有\(Num(\theta, p) = 0\) 对于每一个像素点\((x, y)\),在参数空间中找出所有满足\(xcos\theta + ysin\theta = p\)的\((\theta, p)\)对,然后令\(Num(\theta, p) = Num(\theta, p) + 1\) 统计所有\(Num(\theta, p)\)的大小,取出\(Num(\theta, p) > τ\)的参数(\(τ\)是所设的阈值),从而得到一条直线。 将上述流程取出的直线,确定与其相关线段的起始点与终止点(有一些算法,如蝴蝶形状宽度,峰值走廊之类) 3.2 统计概率霍夫变换算法流程 标准霍夫变换本质上是把图像映射到它的参数空间上,它需要计算所有的M个边缘点,这样它的运算量和所需内存空间都会很大。如果在输入图像中只是处理\(m(m HoughLinesP函数就是利用概率霍夫变换来检测直线的。它的一般步骤为: 随机抽取图像中的一个特征点,即边缘点,如果该点已经被标定为是某一条直线上的点,则继续在剩下的边缘点中随机抽取一个边缘点,直到所有边缘点都抽取完了为止; 对该点进行霍夫变换,并进行累加和计算; 选取在霍夫空间内值最大的点,如果该点大于阈值的,则进行步骤4,否则回到步骤1; 根据霍夫变换得到的最大值,从该点出发,沿着直线的方向位移,从而找到直线的两个端点; 计算直线的长度,如果大于某个阈值,则被认为是好的直线输出,回到步骤1。 4 OpenCV中的霍夫变换函数 4.1标准霍夫变换HoughLines()函数 void HoughLines(InputArray image,OutputArray lines, double rho, double theta, int threshold, double srn=0,double stn=0 ) 第一个参数,InputArray类型的image,输入图像,即源图像,需为8位的单通道二进制图像,可以将任意的源图载入进来后由函数修改成此格式后,再填在这里。 第二个参数,InputArray类型的lines,经过调用HoughLines函数后储存了霍夫线变换检测到线条的输出矢量。每一条线由具有两个元素的矢量\((p, \theta)\)表示,其中,\(p\)是离坐标原点((0,0)(也就是图像的左上角)的距离。 \(\theta\)是弧度线条旋转角度(0垂直线,π/2水平线)。 第三个参数,double类型的rho,以像素为单位的距离精度。另一种形容方式是直线搜索时的进步尺寸的单位半径。PS:Latex中/rho就表示 \(\rho\)。 第四个参数,double类型的theta,以弧度为单位的角度精度。另一种形容方式是直线搜索时的进步尺寸的单位角度。 第五个参数,int类型的threshold,累加平面的阈值参数,即识别某部分为图中的一条直线时它在累加平面中必须达到的值。大于阈值threshold的线段才可以被检测通过并返回到结果中。 第六个参数,double类型的srn,有默认值0。对于多尺度的霍夫变换,这是第三个参数进步尺寸rho的除数距离。粗略的累加器进步尺寸直接是第三个参数rho,而精确的累加器进步尺寸为rho/srn。 第七个参数,double类型的stn,有默认值0,对于多尺度霍夫变换,srn表示第四个参数进步尺寸的单位角度theta的除数距离。且如果srn和stn同时为0,就表示使用经典的霍夫变换。否则,这两个参数应该都为正数。 4.2 统计概率霍夫变换(HoughLinesP) C++: void HoughLinesP(InputArray image, OutputArray lines, double rho, double theta, int threshold, double minLineLength=0, double maxLineGap=0 ) 第一个参数,InputArray类型的image,输入图像,即源图像,需为8位的单通道二进制图像,可以将任意的源图载入进来后由函数修改成此格式后,再填在这里。 第二个参数,InputArray类型的lines,经过调用HoughLinesP函数后后存储了检测到的线条的输出矢量,每一条线由具有四个元素的矢量\((x_1,y_1, x_2, y_2)\)表示,其中,\((x_1, y_1)\)和\((x_2, y_2)\)是每个检测到的线段的结束点。 第三个参数,double类型的rho,以像素为单位的距离精度。另一种形容方式是直线搜索时的进步尺寸的单位半径。 第四个参数,double类型的theta,以弧度为单位的角度精度。另一种形容方式是直线搜索时的进步尺寸的单位角度。 第五个参数,int类型的threshold,累加平面的阈值参数,即识别某部分为图中的一条直线时它在累加平面中必须达到的值。大于阈值threshold的线段才可以被检测通过并返回到结果中。 第六个参数,double类型的minLineLength,有默认值0,表示最低线段的长度,比这个设定参数短的线段就不能被显现出来。 第七个参数,double类型的maxLineGap,有默认值0,允许将同一行点与点之间连接起来的最大的距离。 5 源码分析 此部分参考几位博主的博客,更改了里面一些我认为不太对的地方以及加上了一些自己的理解还有就是一些没有解释的地方 5.1 HoughLines()源码分析 阅读源码之后,发现源码确实细节方面做得比较好,无论是内存方面,还是效率方面,包括一些小细节,比如避免除法,等等。所以源码值得借鉴与反复参考,具体解释如下。 static void icvHoughLinesStandard( const CvMat* img, float rho, float theta, int threshold, CvSeq *lines, int lineMax) { cv::AutoBuffer cv::AutoBuffer const uchar* image; int step, width, height; int numangle, numrho; int total=0; float ang; int r, n; int i, j; float irho = 1 / rho; double scale; //再次确保输入图像的正确性 CV_Assert( CV_IS_MAT(img) && CV_MAT_TYPE(img->type) == CV_8UC1); image = img->data.ptr; //得到图像的指针 step = img->step; //得到图像的步长(通道) width = img->cols; //得到图像的宽 height = img->rows; //得到图像的高 //由角度和距离的分辨率得到角度和距离的数量,即霍夫变换后角度和距离的个数 numangle = cvRound(CV_PI / theta); // 霍夫空间,角度方向的大小 numrho = cvRound(((width + height)*2 + 1) / rho); //r的空间范围, 这里以周长作为rho的上界 /* allocator类是一个模板类,定义在头文件memory中,用于内存的分配、释放、管理,它帮助我们将内存分配和对象构造分离开来。具体地说,allocator类将内存的分配和对象的构造解耦, 分别用allocate和construct两个函数完成,同样将内存的释放和对象的析构销毁解耦,分别用deallocate和destroy函数完成。 */ //为累加器数组分配内存空间 //该累加器数组其实就是霍夫空间,它是用一维数组表示二维空间 _accum.allocate((numangle+2) * (numrho + 2)); //为排序数组分配内存空间 _sort_buf.allocate(numangle * numrho); //为正弦和余弦列表分配内存空间 _tabSin.allocate(numangle); _tabCos.allocate(numangle); //分别定义上述内存空间的地址指针 int *accum = _accum, *sort_buf = _sort_buf; int *tabSin = _tabSin, *tabCos = _tabCos; //累加器数组清零 memset( accum, 0, sizeof(accum[0]) * (numangle+2) * (numrho+2) ); //为避免重复运算,事先计算好sinθi/ρ和cosθi/ρ for( ang = 0, n = 0; n < numangle; ang += theta, n++ ) //计算正弦曲线的准备工作,查表 { tabSin[n] = (float)(sin(ang) * irho); tabCos[n] = (float)(cos(ang) * irho); } //stage 1. fill accumulator //执行步骤1,逐点进行霍夫空间变换,并把结果放入累加器数组内 for( i = 0 ; i < height; i++) for( j = 0; j < width; j++) { //只对图像的非零值处理,即只对图像的边缘像素进行霍夫变换 if( image[i * step + j] != 0 ) //将每个非零点,转换为霍夫空间的离散正弦曲线,并统计。 for( n = 0; n < numangle; n++ ) { //根据公式: ρ = xcosθ + ysinθ //cvRound()函数:四舍五入 r = cvRound( j * tabCos[n] + i * tabSin[n]); //numrho是ρ的最大值,或者说最大取值范围 r += (numrho - 1) / 2; //因为theta是从0到π的,所以cos(theta)是有负的,所以就所有的r += 最大值的一半,让极径都>0 //另一方面,这也预防了r小于0,让本属于这一行的点跑到了上一行,这样可能导致同一个位置却表示了多个不同的“点” //r表示的是距离,n表示的是角点,在累加器内找到它们所对应的位置(即霍夫空间内的位置),其值加1 accum[(n+1) * (numrho+2)+ r + 1]++; /* 将1维数组想象成2维数组 n+1是为了第一行空出来 numrho+2 是总共的列数,这里实际意思应该是半径的所有可能取值,加2是为了防止越界,但是说成列数我觉得也没错,并且我觉得这样比较好理解 r+1 是为了把第一列空出来 因为程序后面要比较前一行与前一列的数据, 这样省的越界 因此空出首行和首列*/ } } // stage 2. find local maximums // 执行步骤2,找到局部极大值,即非极大值抑制 // 霍夫空间,局部最大点,采用四领域判断,比较。(也可以使8邻域或者更大的方式),如果不判断局部最大值,同时选用次大值与最大值,就可能会是两个相邻的直线,但实际是一条直线。 // 选用最大值,也是去除离散的近似计算带来的误差,或合并近似曲线。 for( r = 0 ; r < numrho; r++ ) for( n = 0; n < numangle; n++ ) { //得到当前值在累加器数组的位置 int base = (n+1)*(numrho+2) + r + 1; //得到计数值,并以它为基准,看看它是不是局部极大值 if( accum[base] > threshold && accum[base] > accum[base - 1] && accum[base] >= accum[base+1] && accum[base] > accum[base - numrho - 2] && accum[base] >= accum[base + numrho + 2) //把极大值位置存入排序数组内——sort_buf sort_buf[total++] = base; } //stage 3. sort the detected lines by accumulator value //执行步骤3,对存储在sort_buf数组内的累加器的数据按由大到小的顺序进行排序 icvHoughSortDescent32s( sort_buf, total, accum ); /*OpenCV中自带了一个排序函数,名称为: void icvHoughSortDescent32s(int *sequence , int sum , int*data),参数解释: 第三个参数:数组的首地址 第二个参数:要排序的数据总数目 第一个参数:此数组存放data中要参与排序的数据的序号 而且这个排序算法改变的只是sequence[]数组中的元素,源数据data[]未发生丝毫改变。 */ // stage 4. store the first min(total, linesMax ) lines to the output buffer,输出直线 lineMax = MIN(lineMax, total); //linesMax是输入参数,表示最多输出几条直线 //事先定义一个尺度 scale = 1./(numrho+2); for(i=0; i { //CvLinePolar 直线的数据结构 //CvLinePolar结构在该文件的前面被定义 CvLinePolar line; //idx为极大值在累加器数组的位置 int idx = sort_buf[i]; //找到索引(下标) //分离出该极大值在霍夫空间中的位置 //因为n是从0开始的,而之前为了防止越界,所以将所有的n+1了,因此下面要-1,同理r int n = cvFloor(idx*scale) - 1; //向下取整 int r = idx - (n+1)*(numrho+2) - 1; //最终得到极大值所对应的角度和距离 line.rho = (r - (numrho - 1)*0.5f)*rho; //因为之前统一将r+= (numrho-1)/2, 因此需要还原以获得真实的rho line.angle = n * theta; //存储到序列内 cvSeqPush( lines, &line ); //用序列存放多条直线 } } 5.2 HoughLinesP源码分析 这个代码与之前HoughLines风格完全不同,个人感觉没有之前HoughLines的优美,同时小优化也并不是特别注意,不过实现算法思想的大体思路还是值得我这个初学者借鉴的,但是里面那个shitf操作没看懂,不是很理解,如果有同学会的话,希望解释一下 static void icvHoughLinesProbabilistic( CvMat* image, float rho, float theta, int threshold, int lineLength, int lineGap, CvSeq *lines, int linesMax ) { //accum为累加器矩阵,mask为掩码矩阵 cv::Mat accum, mask; cv::vector //开辟一段内存空间 cv::MemStorage storage(cvCreateMemStorage(0)); //用于存储特征点坐标,即边缘像素的位置 CvSeq* seq; CvSeqWriter writer; int width, height; //图像的宽和高 int numangle, numrho; //角度和距离的离散数量 float ang; int r, n, count; CvPoint pt; float irho = 1 / rho; //距离分辨率的倒数 CvRNG rng = cvRNG(-1); //随机数 const float* ttab; //向量trigtab的地址指针 uchar* mdata0; //矩阵mask的地址指针 //确保输入图像的正确性 CV_Assert( CV_IS_MAT(image) && CV_MAT_TYPE(image->type) == CV_8UC1 ); width = image->cols; //提取出输入图像的宽 height = image->rows; //提取出输入图像的高 //由角度和距离分辨率,得到角度和距离的离散数量 numangle = cvRound(CV_PI / theta); numrho = cvRound(((width + height) * 2 + 1) / rho); //创建累加器矩阵,即霍夫空间 accum.create( numangle, numrho, CV_32SC1 ); //创建掩码矩阵,大小与输入图像相同 mask.create( height, width, CV_8UC1 ); //定义trigtab的大小,因为要存储正弦和余弦值,所以长度为角度离散数的2倍 trigtab.resize(numangle*2); //累加器矩阵清零 accum = cv::Scalar(0); //避免重复计算,事先计算好所需的所有正弦和余弦值 for( ang = 0, n = 0; n < numangle; ang += theta, n++ ) { trigtab[n*2] = (float)(cos(ang) * irho); trigtab[n*2+1] = (float)(sin(ang) * irho); } //赋值首地址 ttab = &trigtab[0]; mdata0 = mask.data; //开始写入序列 cvStartWriteSeq( CV_32SC2, sizeof(CvSeq), sizeof(CvPoint), storage, &writer ); // stage 1. collect non-zero image points //收集图像中的所有非零点,因为输入图像是边缘图像,所以非零点就是边缘点 for( pt.y = 0, count = 0; pt.y < height; pt.y++ ) { //提取出输入图像和掩码矩阵的每行地址指针 const uchar* data = image->data.ptr + pt.y*image->step; // step是每一行的字节大小 此行代码就转到当前遍历的这一行 uchar* mdata = mdata0 + pt.y*width; for( pt.x = 0; pt.x < width; pt.x++ ) { if( data[pt.x] ) //是边缘点 { mdata[pt.x] = (uchar)1; //掩码的相应位置置1 CV_WRITE_SEQ_ELEM( pt, writer ); 把该坐标位置写入序列 } else //不是边缘点 mdata[pt.x] = 0; //掩码的相应位置清0 } } //终止写序列,seq为所有边缘点坐标位置的序列 seq = cvEndWriteSeq( &writer ); count = seq->total; //得到边缘点的数量 // stage 2. process all the points in random order //随机处理所有的边缘点 for( ; count > 0; count-- ) { // choose random point out of the remaining ones //步骤1,在剩下的边缘点中随机选择一个点,idx为不大于count的随机数 int idx = cvRandInt(&rng) % count; //max_val为累加器的最大值,max_n为最大值所对应的角度 int max_val = threshold-1, max_n = 0; //由随机数idx在序列中提取出所对应的坐标点 CvPoint* point = (CvPoint*)cvGetSeqElem( seq, idx ); //定义直线的两个端点 CvPoint line_end[2] = {{0,0}, {0,0}}; float a, b; //累加器的地址指针,也就是霍夫空间的地址指针 int* adata = (int*)accum.data; int i, j, k, x0, y0, dx0, dy0, xflag; int good_line; const int shift = 16; // //提取出坐标点的横、纵坐标 i = point->y; j = point->x; // "remove" it by overriding it with the last element //用序列中的最后一个元素覆盖掉刚才提取出来的随机坐标点 *point = *(CvPoint*)cvGetSeqElem( seq, count-1 ); // check if it has been excluded already (i.e. belongs to some other line) //检测这个坐标点是否已经计算过,也就是它已经属于其他直线 //因为计算过的坐标点会在掩码矩阵mask的相对应位置清零 if( !mdata0[i*width + j] ) //该坐标点被处理过 continue; //不做任何处理,继续主循环 // update accumulator, find the most probable line //步骤2,更新累加器矩阵,找到最有可能的直线 for( n = 0; n < numangle; n++, adata += numrho ) { //由角度计算距离 r = cvRound( j * ttab[n*2] + i * ttab[n*2+1] ); r += (numrho - 1) / 2; //防止r为负数 //在累加器矩阵的相应位置上数值加1,并赋值给val int val = ++adata[r]; //更新最大值,并得到它的角度 if( max_val < val ) { max_val = val; max_n = n; } } // if it is too "weak" candidate, continue with another point //步骤3,如果上面得到的最大值小于阈值,则放弃该点,继续下一个点的计算 if( max_val < threshold ) continue; // from the current point walk in each direction // along the found line and extract the line segment //步骤4,从当前点出发,沿着它所在直线的方向前进,直到达到端点为止 a = -ttab[max_n*2+1]; //a=-sinθ b = ttab[max_n*2]; //b=cosθ //当前点的横、纵坐标值 x0 = j; y0 = i; //确定当前点所在直线的角度是在45度~135度之间,还是在0~45或135度~180度之间 if( fabs(a) > fabs(b) ) //在45度~135度之间 { xflag = 1; //置标识位,标识直线的粗略方向 //确定横、纵坐标的位移量 dx0 = a > 0 ? 1 : -1; dy0 = cvRound( b*(1 << shift)/fabs(a) ); //确定纵坐标 y0 = (y0 << shift) + (1 << (shift-1)); } else //在0~45或135度~180度之间 { xflag = 0; //清标识位 //确定横、纵坐标的位移量 dy0 = b > 0 ? 1 : -1; dx0 = cvRound( a*(1 << shift)/fabs(b) ); //确定横坐标 x0 = (x0 << shift) + (1 << (shift-1)); } //搜索直线的两个端点 for( k = 0; k < 2; k++ ) { //gap表示两条直线的间隙,x和y为搜索位置,dx和dy为位移量 int gap = 0, x = x0, y = y0, dx = dx0, dy = dy0; //搜索第二个端点的时候,反方向位移 if( k > 0 ) dx = -dx, dy = -dy; // walk along the line using fixed-point arithmetics, // stop at the image border or in case of too big gap //沿着直线的方向位移,直到到达图像的边界或大的间隙为止 for( ;; x += dx, y += dy ) { uchar* mdata; int i1, j1; //确定新的位移后的坐标位置 if( xflag ) { j1 = x; i1 = y >> shift; } else { j1 = x >> shift; i1 = y; } //如果到达了图像的边界,停止位移,退出循环 if( j1 < 0 || j1 >= width || i1 < 0 || i1 >= height ) break; //定位位移后掩码矩阵位置 mdata = mdata0 + i1*width + j1; // for each non-zero point: // update line end, // clear the mask element // reset the gap //该掩码不为0,说明该点可能是在直线上 if( *mdata ) { gap = 0; //设置间隙为0 //更新直线的端点位置 line_end[k].y = i1; line_end[k].x = j1; } //掩码为0,说明不是直线,但仍继续位移,直到间隙大于所设置的阈值为止 else if( ++gap > lineGap ) //间隙加1 break; } } //步骤5,由检测到的直线的两个端点粗略计算直线的长度 //当直线长度大于所设置的阈值时,good_line为1,否则为0 good_line = abs(line_end[1].x - line_end[0].x) >= lineLength || abs(line_end[1].y - line_end[0].y) >= lineLength; //再次搜索端点,目的是更新累加器矩阵和更新掩码矩阵,以备下一次循环使用 for( k = 0; k < 2; k++ ) { int x = x0, y = y0, dx = dx0, dy = dy0; if( k > 0 ) dx = -dx, dy = -dy; // walk along the line using fixed-point arithmetics, // stop at the image border or in case of too big gap for( ;; x += dx, y += dy ) { uchar* mdata; int i1, j1; if( xflag ) { j1 = x; i1 = y >> shift; } else { j1 = x >> shift; i1 = y; } mdata = mdata0 + i1*width + j1; // for each non-zero point: // update line end, // clear the mask element // reset the gap if( *mdata ) { //if语句的作用是清除那些已经判定是好的直线上的点对应的累加器的值,避免再次利用这些累加值 if( good_line ) //在第一次搜索中已经确定是好的直线 { //得到累加器矩阵地址指针 adata = (int*)accum.data; for( n = 0; n < numangle; n++, adata += numrho ) { r = cvRound( j1 * ttab[n*2] + i1 * ttab[n*2+1] ); r += (numrho - 1) / 2; adata[r]--; //相应的累加器减1 } } //搜索过的位置,不管是好的直线,还是坏的直线,掩码相应位置都清0,这样下次就不会再重复搜索这些位置了,从而达到减小计算边缘点的目的 *mdata = 0; } //如果已经到达了直线的端点,则退出循环 if( i1 == line_end[k].y && j1 == line_end[k].x ) break; } } //如果是好的直线 if( good_line ) { CvRect lr = { line_end[0].x, line_end[0].y, line_end[1].x, line_end[1].y }; //把两个端点压入序列中 cvSeqPush( lines, &lr ); //如果检测到的直线数量大于阈值,则退出该函数 if( lines->total >= linesMax ) return; } } } 6 霍夫圆变换原理及算法流程 6.1 经典霍夫圆变换 霍夫圆变换和霍夫线变换的原理类似。霍夫线变换是两个参数(r,θ),霍夫圆需要三个参数,圆心的x,y坐标和圆的半径,他的方程表达式为\((x-a)^{2} + (y-b)^{2} = c^{2}\),按照标准霍夫线变换思想,在xy平面,三个点在同一个圆上,则它们对应的空间曲面相交于一点(即点(a,b,c))。故我们如果知道一个边界上的点的数目,足够多,且这些点与之对应的空间曲面相交于一点。则这些点构成的边界,就接近一个圆形。上述描述的是标准霍夫圆变换的原理,由于三维空间的计算量大大增大的原因, 标准霍夫圆变化很难被应用到实际中。 具体可以参考下图: 6.2 霍夫梯度法的原理即算法流程(两个版本的解释) HoughCircles函数实现了圆形检测,它使用的算法也是改进的霍夫变换——2-1霍夫变换(21HT)。也就是把霍夫变换分为两个阶段,从而减小了霍夫空间的维数。第一阶段用于检测圆心,第二阶段从圆心推导出圆半径。检测圆心的原理是圆心是它所在圆周所有法线的交汇处,因此只要找到这个交点,即可确定圆心,该方法所用的霍夫空间与图像空间的性质相同,因此它仅仅是二维空间。检测圆半径的方法是从圆心到圆周上的任意一点的距离(即半径)是相同,只要确定一个阈值,只要相同距离的数量大于该阈值,我们就认为该距离就是该圆心所对应的圆半径,该方法只需要计算半径直方图,不使用霍夫空间。圆心和圆半径都得到了,那么通过公式1一个圆形就得到了。从上面的分析可以看出,2-1霍夫变换把标准霍夫变换的三维霍夫空间缩小为二维霍夫空间,因此无论在内存的使用上还是在运行效率上,2-1霍夫变换都远远优于标准霍夫变换。但该算法有一个不足之处就是由于圆半径的检测完全取决于圆心的检测,因此如果圆心检测出现偏差,那么圆半径的检测肯定也是错误的。 version 1: 2-1霍夫变换的具体步骤为: 1)首先对图像进行边缘检测,调用opencv自带的cvCanny()函数,将图像二值化,得到边缘图像。 2)对边缘图像上的每一个非零点。采用cvSobel()函数,计算x方向导数和y方向的导数,从而得到梯度。从边缘点,沿着梯度和梯度的反方向,对参数指定的min_radius到max_radium的每一个像素,在累加器中被累加。同时记下边缘图像中每一个非0点的位置。 3)从(二维)累加器中这些点中选择候选中心。这些中心都大于给定的阈值和其相邻的四个邻域点的累加值。 4)对于这些候选中心按照累加值降序排序,以便于最支持的像素的中心首次出现。 5)对于每一个中心,考虑到所有的非0像素(非0,梯度不为0),这些像素按照与其中心的距离排序,从最大支持的中心的最小距离算起,选择非零像素最支持的一条半径。 6)如果一个中心受到边缘图像非0像素的充分支持,并且到前期被选择的中心有足够的距离。则将圆心和半径压入到序列中,得以保留。 version 2: 第一阶段:检测圆心 1.1、对输入图像边缘检测; 1.2、计算图形的梯度,并确定圆周线,其中圆周的梯度就是它的法线; 1.3、在二维霍夫空间内,绘出所有图形的梯度直线,某坐标点上累加和的值越大,说明在该点上直线相交的次数越多,也就是越有可能是圆心;(备注:这只是直观的想法,实际源码并没有划线) 1.4、在霍夫空间的4邻域内进行非最大值抑制; 1.5、设定一个阈值,霍夫空间内累加和大于该阈值的点就对应于圆心。 第二阶段:检测圆半径 2.1、计算某一个圆心到所有圆周线的距离,这些距离中就有该圆心所对应的圆的半径的值,这些半径值当然是相等的,并且这些圆半径的数量要远远大于其他距离值相等的数量 2.2、设定两个阈值,定义为最大半径和最小半径,保留距离在这两个半径之间的值,这意味着我们检测的圆不能太大,也不能太小 2.3、对保留下来的距离进行排序 2.4、找到距离相同的那些值,并计算相同值的数量 2.5、设定一个阈值,只有相同值的数量大于该阈值,才认为该值是该圆心对应的圆半径 2.6、对每一个圆心,完成上面的2.1~2.5步骤,得到所有的圆半径 7 OpenCV圆变换函数 HoughCircles C++: void HoughCircles(InputArray image,OutputArray circles, int method, double dp, double minDist, double param1=100,double param2=100, int minRadius=0, int maxRadius=0 ) 第一个参数,InputArray类型的image,输入图像,即源图像,需为8位的灰度单通道图像。 第二个参数,InputArray类型的circles,经过调用HoughCircles函数后此参数存储了检测到的圆的输出矢量,每个矢量由包含了3个元素的浮点矢量(x, y, radius)表示。 第三个参数,int类型的method,即使用的检测方法,目前OpenCV中就霍夫梯度法一种可以使用,它的标识符为CV_HOUGH_GRADIENT,在此参数处填这个标识符即可。 第四个参数,double类型的dp,用来检测圆心的累加器图像的分辨率于输入图像之比的倒数,且此参数允许创建一个比输入图像分辨率低的累加器。上述文字不好理解的话,来看例子吧。例如,如果dp= 1时,累加器和输入图像具有相同的分辨率。如果dp=2,累加器便有输入图像一半那么大的宽度和高度。 第五个参数,double类型的minDist,为霍夫变换检测到的圆的圆心之间的最小距离,即让我们的算法能明显区分的两个不同圆之间的最小距离。这个参数如果太小的话,多个相邻的圆可能被错误地检测成了一个重合的圆。反之,这个参数设置太大的话,某些圆就不能被检测出来了。 第六个参数,double类型的param1,有默认值100。它是第三个参数method设置的检测方法的对应的参数。对当前唯一的方法霍夫梯度法CV_HOUGH_GRADIENT,它表示传递给canny边缘检测算子的高阈值,而低阈值为高阈值的一半。 第七个参数,double类型的param2,也有默认值100。它是第三个参数method设置的检测方法的对应的参数。对当前唯一的方法霍夫梯度法CV_HOUGH_GRADIENT,它表示在检测阶段圆心的累加器阈值。它越小的话,就可以检测到更多根本不存在的圆,而它越大的话,能通过检测的圆就更加接近完美的圆形了。 第八个参数,int类型的minRadius,有默认值0,表示圆半径的最小值。 第九个参数,int类型的maxRadius,也有默认值0,表示圆半径的最大值。 8 源码分析 有两个版本的注释,一样的,结合来看 其中几个点: 霍夫空间是用于统计坐标点,分辨率没有必要与原图像一致,所以用dp来调整霍夫空间的大小,从而提高运算速度。而ONE的作用是为了减小运算过程中的累积误差,提高精度,如:1/3=0.333333,如果保留小数点后5位,则为0.33333,但如果向左位移3位,则为333.33333,这个数的精度要比前一个高,只要我们把所有的数都向左位移3位,最终的结果再向右位移3位,最后的数值精度会提高不少的。基本思想就是这个。 8.1 version1:论文中的 /****************************************************************************************\ * Circle Detection * \****************************************************************************************/ /*------------------------------------霍夫梯度法------------------------------------------*/ static void icvHoughCirclesGradient( CvMat* img, float dp, float min_dist, int min_radius, int max_radius, int canny_threshold, int acc_threshold, CvSeq* circles, int circles_max ) { const int SHIFT = 10, ONE = 1 << SHIFT, R_THRESH = 30; //One=1024,1左移10位2*10,R_THRESH是起始值,赋给max_count,后续会被覆盖。 cv::Ptr cv::Ptr std::vector cv::Ptr int x, y, i, j, k, center_count, nz_count;//center_count为圆心数,nz_count为非零数 float min_radius2 = (float)min_radius*min_radius;//最小半径的平方 float max_radius2 = (float)max_radius*max_radius;//最大半径的平方 int rows, cols, arows,acols;//rows,cols边缘图像的行数和列数,arows,acols是累加器图像的行数和列数 int astep, *adata;//adata指向累加器数据域的首地址,用位置作为下标,astep为累加器每行的大小,以字节为单位 float* ddata;//ddata即dist_data,距离数据 CvSeq *nz, *centers;//nz为非0,即边界,centers为存放的候选中心的位置。 float idp, dr;//idp即inv_dp,dp的倒数 CvSeqReader reader;//顺序读取序列中的每个值 edges = cvCreateMat( img->rows, img->cols, CV_8UC1 );//边缘图像 cvCanny( img, edges, MAX(canny_threshold/2,1), canny_threshold, 3 );//调用canny,变为二值图像,0和非0即0和255 dx = cvCreateMat( img->rows, img->cols, CV_16SC1 );//16位单通道图像,用来存储二值边缘图像的x方向的一阶导数 dy = cvCreateMat( img->rows, img->cols, CV_16SC1 );//y方向的 cvSobel( img, dx, 1, 0, 3 );//计算x方向的一阶导数 cvSobel( img, dy, 0, 1, 3 );//计算y方向的一阶导数 if( dp < 1.f )//控制dp不能比1小 dp = 1.f; idp = 1.f/dp; accum = cvCreateMat( cvCeil(img->rows*idp)+2, cvCeil(img->cols*idp)+2, CV_32SC1 );//cvCeil返回不小于参数的最小整数。32为单通道 cvZero(accum);//初始化累加器为0 storage = cvCreateMemStorage();//创建内存存储器,使用默认参数0.默认大小为64KB nz = cvCreateSeq( CV_32SC2, sizeof(CvSeq), sizeof(CvPoint), storage );//创建序列,用来存放非0点 centers = cvCreateSeq( CV_32SC1, sizeof(CvSeq), sizeof(int), storage );//用来存放圆心 rows = img->rows; cols = img->cols; arows = accum->rows - 2; acols = accum->cols - 2; adata = accum->data.i;//cvMat对象的union对象的i成员成员 //step是矩阵中行的长度,单位为字节。我们使用到的矩阵是accum它的深度是CV_32SC1即32位的int 型。 //如果我们知道一个指针如int* p;指向数组中的一个元素, 则可以通过p+accum->step/adata[0]来使指针移动到p指针所指元素的,正对的下一行元素 astep = accum->step/sizeof(adata[0]); for( y = 0; y < rows; y++ ) { const uchar* edges_row = edges->data.ptr + y*edges->step; //边界存储的矩阵的每一行的指向行首的指针。 const short* dx_row = (const short*)(dx->data.ptr + y*dx->step);//存储 x方向sobel一阶导数的矩阵的每一行的指向第一个元素的指针 const short* dy_row = (const short*)(dy->data.ptr + y*dy->step);//y //遍历边缘的二值图像和偏导数的图像 for( x = 0; x < cols; x++ ) { float vx, vy; int sx, sy, x0, y0, x1, y1, r, k; CvPoint pt; vx = dx_row[x];//访问每一行的元素 vy = dy_row[x]; if( !edges_row[x] || (vx == 0 && vy == 0) )//如果在边缘图像(存储边缘的二值图像)某一点如A(x0,y0)==0则对一下点进行操作。vx和vy同时为0,则下一个 continue; float mag = sqrt(vx*vx+vy*vy);//求梯度图像 assert( mag >= 1 );//如果mag为0,说明没有边缘点,则stop。这里用了assert宏定义 sx = cvRound((vx*idp)*ONE/mag);// vx为该点的水平梯度(梯度幅值已经归一化);ONE为为了用整数运算代替浮点数引入的一个因子,为2^10 sy = cvRound((vy*idp)*ONE/mag); x0 = cvRound((x*idp)*ONE); y0 = cvRound((y*idp)*ONE); for( k = 0; k < 2; k++ )//k=0在梯度方向,k=1在梯度反方向对累加器累加。这里之所以要反向,因为对于一个圆上一个点,从这个点沿着斜率的方向的,最小半径到最大半径。在圆的另一边与其相对应的点,有对应的效果。 { x1 = x0 + min_radius * sx; y1 = y0 + min_radius * sy; for( r = min_radius; r <= max_radius; x1 += sx, y1 += sy, r++ )//x1=x1+sx即,x1=x0+min_radius*sx+sx=x0+(min_radius+1)*sx求得下一个点。sx为斜率 { int x2 = x1 >> SHIFT, y2 = y1 >> SHIFT; //变回真实的坐标 if( (unsigned)x2 >= (unsigned)acols || //如果x2大于累加器的行 (unsigned)y2 >= (unsigned)arows ) break; adata[y2*astep + x2]++;//由于c语言是按行存储的。即等价于对accum数组进行了操作。 } sx = -sx; sy = -sy; } pt.x = x; pt.y = y; cvSeqPush( nz, &pt );//把非零边缘并且梯度不为0的点压入到堆栈 } } nz_count = nz->total; if( !nz_count )//如果nz_count==0则返回 return; for( y = 1; y < arows - 1; y++ ) //这里是从1到arows-1,因为如果是圆的话,那么圆的半径至少为1,即圆心至少在内层里面 { for( x = 1; x < acols - 1; x++ ) { int base = y*(acols+2) + x;//计算位置,在accum图像中 if( adata[base] > acc_threshold && adata[base] > adata[base-1] && adata[base] > adata[base+1] && adata[base] > adata[base-acols-2] && adata[base] > adata[base+acols+2] ) cvSeqPush(centers, &base);//候选中心点位置压入到堆栈。其候选中心点累加数大于阈值,其大于四个邻域 } } center_count = centers->total; if( !center_count ) //如果没有符合条件的圆心,则返回到函数。 return; sort_buf.resize( MAX(center_count,nz_count) );//重新分配容器的大小,取候选圆心的个数和非零边界的个数的最大值。因为后面两个均用到排序。 cvCvtSeqToArray( centers, &sort_buf[0] ); //把序列转换成数组,即把序列centers中的数据放入到sort_buf的容器中。 icvHoughSortDescent32s( &sort_buf[0], center_count, adata );//快速排序,根据sort_buf中的值作为下标,依照adata中对应的值进行排序,将累加值大的下标排到前面 cvClearSeq( centers );//清空序列 cvSeqPushMulti( centers, &sort_buf[0], center_count );//重新将中心的下标存入centers dist_buf = cvCreateMat( 1, nz_count, CV_32FC1 );//创建一个32为浮点型的一个行向量 ddata = dist_buf->data.fl;//使ddata执行这个行向量的首地址 dr = dp; min_dist = MAX( min_dist, dp );//如果输入的最小距离小于dp,则设在为dp min_dist *= min_dist; for( i = 0; i < centers->total; i++ ) //对于每一个中心点 { int ofs = *(int*)cvGetSeqElem( centers, i );//获取排序的中心位置,adata值最大的元素,排在首位 ,offset偏移位置 y = ofs/(acols+2) - 1;//这里因为edge图像比accum图像小两个边。 x = ofs - (y+1)*(acols+2) - 1;//求得y坐标 float cx = (float)(x*dp), cy = (float)(y*dp); float start_dist, dist_sum; float r_best = 0, c[3]; int max_count = R_THRESH; for( j = 0; j < circles->total; j++ )//中存储已经找到的圆;若当前候选圆心与其中的一个圆心距离 { float* c = (float*)cvGetSeqElem( circles, j );//获取序列中的元素。 if( (c[0] - cx)*(c[0] - cx) + (c[1] - cy)*(c[1] - cy) < min_dist ) break; } if( j < circles->total )//当前候选圆心与任意已检测的圆心距离不小于min_dist时,才有j==circles->total continue; cvStartReadSeq( nz, &reader ); for( j = k = 0; j < nz_count; j++ )//每个候选圆心,对于所有的点 { CvPoint pt; float _dx, _dy, _r2; CV_READ_SEQ_ELEM( pt, reader ); _dx = cx - pt.x; _dy = cy - pt.y; //中心点到边界的距离 _r2 = _dx*_dx + _dy*_dy; if(min_radius2 <= _r2 && _r2 <= max_radius2 ) { ddata[k] = _r2; //把满足的半径的平方存起来 sort_buf[k] = k;//sort_buf同上,但是这里的sort_buf的下标值和元素值是相同的,重新利用 k++;//k和j是两个游标 } } int nz_count1 = k, start_idx = nz_count1 - 1; if( nz_count1 == 0 ) continue; //如果一个候选中心到(非零边界且梯度>0)确定的点的距离中,没有满足条件的,则从下一个中心点开始。 dist_buf->cols = nz_count1;//用来存放真是的满足条件的非零元素(三个约束:非零点,梯度不为0,到圆心的距离在min_radius和max_radius中间) cvPow( dist_buf, dist_buf, 0.5 );//对dist_buf中的元素开根号.求得半径 icvHoughSortDescent32s( &sort_buf[0], nz_count1, (int*)ddata );////对与圆心的距离按降序排列,索引值在sort_buf中 dist_sum = start_dist = ddata[sort_buf[nz_count1-1]];//dist距离,选取半径最小的作为起始值 //下边for循环里面是一个算法。它定义了两个游标(指针)start_idx和j,j是外层循环的控制变量。而start_idx为控制当两个相邻的数组ddata的数据发生变化时,即d-start_dist>dr时,的步进。 for( j = nz_count1 - 2; j >= 0; j-- )//从小到大。选出半径支持点数最多的半径 { float d = ddata[sort_buf[j]]; if( d > max_radius )//如果求得的候选圆点到边界的距离大于参数max_radius,则停止,因为d是第一个出现的最小的(按照从大到小的顺序排列的) break; if( d - start_dist > dr )//如果当前的距离减去最小的>dr(==dp) { float r_cur = ddata[sort_buf[(j + start_idx)/2]];//当前半径设为符合该半径的中值,j和start_idx相当于两个游标 if( (start_idx - j)*r_best >= max_count*r_cur || //如果数目相等时,它会找半径较小的那个。这里是判断支持度的算法 (r_best < FLT_EPSILON && start_idx - j >= max_count) ) //程序这个部分告诉我们,无法找到同心圆,它会被外层最大,支持度最多(支持的点最多)所覆盖。 { r_best = r_cur;//如果 符合当前半径的点数(start_idx - j)/ 当前半径>= 符合之前最优半径的点数/之前的最优半径 || 还没有最优半径时,且点数>30时;其实直接把r_best初始值置为1即可省去第二个条件 max_count = start_idx - j;//maxcount变为符合当前半径的点数,更新max_count值,后续的支持度大的半径将会覆盖前面的值。 } start_dist = d; start_idx = j; dist_sum = 0;//如果距离改变较大,则重置distsum为0,再在下面的式子中置为当前值 } dist_sum += d;//如果距离改变较小,则加上当前值(dist_sum)在这里好像没有用处。 } if( max_count > R_THRESH )//符合条件的圆周点大于阈值30,则将圆心、半径压栈 { c[0] = cx; c[1] = cy; c[2] = (float)r_best; cvSeqPush( circles, c ); if( circles->total > circles_max )//circles_max是个很大的数,其值为INT_MAX return; } } } CV_IMPL CvSeq* cvHoughCircles1( CvArr* src_image, void* circle_storage, int method, double dp, double min_dist, double param1, double param2, int min_radius, int max_radius ) { CvSeq* result = 0; CvMat stub, *img = (CvMat*)src_image; CvMat* mat = 0; CvSeq* circles = 0; CvSeq circles_header; CvSeqBlock circles_block; int circles_max = INT_MAX; int canny_threshold = cvRound(param1);//cvRound返回和参数最接近的整数值,对一个double类型进行四舍五入 int acc_threshold = cvRound(param2); img = cvGetMat( img, &stub );//将img转化成为CvMat对象 if( !CV_IS_MASK_ARR(img)) //图像必须为8位,单通道图像 CV_Error( CV_StsBadArg, "The source image must be 8-bit, single-channel" ); if( !circle_storage ) CV_Error( CV_StsNullPtr, "NULL destination" ); if( dp <= 0 || min_dist <= 0 || canny_threshold <= 0 || acc_threshold <= 0 ) CV_Error( CV_StsOutOfRange, "dp, min_dist, canny_threshold and acc_threshold must be all positive numbers" ); min_radius = MAX( min_radius, 0 ); if( max_radius <= 0 )//用来控制当使用默认参数max_radius=0的时候 max_radius = MAX( img->rows, img->cols ); else if( max_radius <= min_radius ) max_radius = min_radius + 2; if( CV_IS_STORAGE( circle_storage ))//如果传入的是内存存储器 { circles = cvCreateSeq( CV_32FC3, sizeof(CvSeq), sizeof(float)*3, (CvMemStorage*)circle_storage ); } else if( CV_IS_MAT( circle_storage ))//如果传入的参数时数组 { mat = (CvMat*)circle_storage; //数组应该是CV_32FC3类型的单列数组。 if( !CV_IS_MAT_CONT( mat->type ) || (mat->rows != 1 && mat->cols != 1) ||//连续,单列,CV_32FC3类型 CV_MAT_TYPE(mat->type) != CV_32FC3 ) CV_Error( CV_StsBadArg, "The destination matrix should be continuous and have a single row or a single column" ); //将数组转换为序列 circles = cvMakeSeqHeaderForArray( CV_32FC3, sizeof(CvSeq), sizeof(float)*3, mat->data.ptr, mat->rows + mat->cols - 1, &circles_header, &circles_block );//由于是单列,故elem_size为mat->rows+mat->cols-1 circles_max = circles->total; cvClearSeq( circles );//清空序列的内容(如果传入的有数据的话) } else CV_Error( CV_StsBadArg, "Destination is not CvMemStorage* nor CvMat*" ); switch( method ) { case CV_HOUGH_GRADIENT: icvHoughCirclesGradient( img, (float)dp, (float)min_dist, min_radius, max_radius, canny_threshold, acc_threshold, circles, circles_max ); break; default: CV_Error( CV_StsBadArg, "Unrecognized method id" ); } if( mat )//给定一个指向圆存储的数组指针值,则返回0,即NULL { if( mat->cols > mat->rows )//因为不知道传入的是列向量还是行向量。 mat->cols = circles->total; else mat->rows = circles->total; } else//如果是传入的是内存存储器,则返回一个指向一个序列的指针。 result = circles; return result; } 8.2 version2:(赵老师) static void icvHoughCirclesGradient( CvMat* img, float dp, float min_dist, int min_radius, int max_radius, int canny_threshold, int acc_threshold, CvSeq* circles, int circles_max ) { //为了提高运算精度,定义一个数值的位移量 const int SHIFT = 10, ONE = 1 << SHIFT; //定义水平梯度和垂直梯度矩阵的地址指针 cv::Ptr //定义边缘图像、累加器矩阵和半径距离矩阵的地址指针 cv::Ptr //定义排序向量 std::vector cv::Ptr int x, y, i, j, k, center_count, nz_count; //事先计算好最小半径和最大半径的平方 float min_radius2 = (float)min_radius*min_radius; float max_radius2 = (float)max_radius*max_radius; int rows, cols, arows, acols; int astep, *adata; float* ddata; //nz表示圆周序列,centers表示圆心序列 CvSeq *nz, *centers; float idp, dr; CvSeqReader reader; //创建一个边缘图像矩阵 edges = cvCreateMat( img->rows, img->cols, CV_8UC1 ); //第一阶段 //步骤1.1,用canny边缘检测算法得到输入图像的边缘图像 cvCanny( img, edges, MAX(canny_threshold/2,1), canny_threshold, 3 ); //创建输入图像的水平梯度图像和垂直梯度图像 dx = cvCreateMat( img->rows, img->cols, CV_16SC1 ); dy = cvCreateMat( img->rows, img->cols, CV_16SC1 ); //步骤1.2,用Sobel算子法计算水平梯度和垂直梯度 cvSobel( img, dx, 1, 0, 3 ); cvSobel( img, dy, 0, 1, 3 ); /确保累加器矩阵的分辨率不小于1 if( dp < 1.f ) dp = 1.f; //分辨率的倒数 idp = 1.f/dp; //根据分辨率,创建累加器矩阵 accum = cvCreateMat( cvCeil(img->rows*idp)+2, cvCeil(img->cols*idp)+2, CV_32SC1 ); //初始化累加器为0 cvZero(accum); //创建两个序列, storage = cvCreateMemStorage(); nz = cvCreateSeq( CV_32SC2, sizeof(CvSeq), sizeof(CvPoint), storage ); centers = cvCreateSeq( CV_32SC1, sizeof(CvSeq), sizeof(int), storage ); rows = img->rows; //图像的高 cols = img->cols; //图像的宽 arows = accum->rows - 2; //累加器的高 acols = accum->cols - 2; //累加器的宽 adata = accum->data.i; //累加器的地址指针 astep = accum->step/sizeof(adata[0]); /累加器的步长 // Accumulate circle evidence for each edge pixel //步骤1.3,对边缘图像计算累加和 for( y = 0; y < rows; y++ ) { //提取出边缘图像、水平梯度图像和垂直梯度图像的每行的首地址 const uchar* edges_row = edges->data.ptr + y*edges->step; const short* dx_row = (const short*)(dx->data.ptr + y*dx->step); const short* dy_row = (const short*)(dy->data.ptr + y*dy->step); for( x = 0; x < cols; x++ ) { float vx, vy; int sx, sy, x0, y0, x1, y1, r; CvPoint pt; //当前的水平梯度值和垂直梯度值 vx = dx_row[x]; vy = dy_row[x]; //如果当前的像素不是边缘点,或者水平梯度值和垂直梯度值都为0,则继续循环。因为如果满足上面条件,该点一定不是圆周上的点 if( !edges_row[x] || (vx == 0 && vy == 0) ) continue; //计算当前点的梯度值 float mag = sqrt(vx*vx+vy*vy); assert( mag >= 1 ); //定义水平和垂直的位移量 sx = cvRound((vx*idp)*ONE/mag); sy = cvRound((vy*idp)*ONE/mag); //把当前点的坐标定位到累加器的位置上 x0 = cvRound((x*idp)*ONE); y0 = cvRound((y*idp)*ONE); // Step from min_radius to max_radius in both directions of the gradient //在梯度的两个方向上进行位移,并对累加器进行投票累计 for(int k1 = 0; k1 < 2; k1++ ) { //初始一个位移的启动 //位移量乘以最小半径,从而保证了所检测的圆的半径一定是大于最小半径 x1 = x0 + min_radius * sx; y1 = y0 + min_radius * sy; //在梯度的方向上位移 // r <= max_radius保证了所检测的圆的半径一定是小于最大半径 for( r = min_radius; r <= max_radius; x1 += sx, y1 += sy, r++ ) { int x2 = x1 >> SHIFT, y2 = y1 >> SHIFT; //如果位移后的点超过了累加器矩阵的范围,则退出 if( (unsigned)x2 >= (unsigned)acols || (unsigned)y2 >= (unsigned)arows ) break; //在累加器的相应位置上加1 adata[y2*astep + x2]++; } //把位移量设置为反方向 sx = -sx; sy = -sy; } //把输入图像中的当前点(即圆周上的点)的坐标压入序列圆周序列nz中 pt.x = x; pt.y = y; cvSeqPush( nz, &pt ); } } //计算圆周点的总数 nz_count = nz->total; //如果总数为0,说明没有检测到圆,则退出该函数 if( !nz_count ) return; //Find possible circle centers //步骤1.4和1.5,遍历整个累加器矩阵,找到可能的圆心 for( y = 1; y < arows - 1; y++ ) { for( x = 1; x < acols - 1; x++ ) { int base = y*(acols+2) + x; //如果当前的值大于阈值,并在4邻域内它是最大值,则该点被认为是圆心 if( adata[base] > acc_threshold && adata[base] > adata[base-1] && adata[base] > adata[base+1] && adata[base] > adata[base-acols-2] && adata[base] > adata[base+acols+2] ) //把当前点的地址压入圆心序列centers中 cvSeqPush(centers, &base); } } //计算圆心的总数 center_count = centers->total; //如果总数为0,说明没有检测到圆,则退出该函数 if( !center_count ) return; //定义排序向量的大小 sort_buf.resize( MAX(center_count,nz_count) ); //把圆心序列放入排序向量中 cvCvtSeqToArray( centers, &sort_buf[0] ); //对圆心按照由大到小的顺序进行排序 //它的原理是经过icvHoughSortDescent32s函数后,以sort_buf中元素作为adata数组下标,adata中的元素降序排列,即adata[sort_buf[0]]是adata所有元素中最大的,adata[sort_buf[center_count-1]]是所有元素中最小的 icvHoughSortDescent32s( &sort_buf[0], center_count, adata ); //清空圆心序列 cvClearSeq( centers ); //把排好序的圆心重新放入圆心序列中 cvSeqPushMulti( centers, &sort_buf[0], center_count ); //创建半径距离矩阵 dist_buf = cvCreateMat( 1, nz_count, CV_32FC1 ); //定义地址指针 ddata = dist_buf->data.fl; dr = dp; //定义圆半径的距离分辨率 //重新定义圆心之间的最小距离 min_dist = MAX( min_dist, dp ); //最小距离的平方 min_dist *= min_dist; // For each found possible center // Estimate radius and check support //按照由大到小的顺序遍历整个圆心序列 for( i = 0; i < centers->total; i++ ) { //提取出圆心,得到该点在累加器矩阵中的偏移量 int ofs = *(int*)cvGetSeqElem( centers, i ); //得到圆心在累加器中的坐标位置 y = ofs/(acols+2); x = ofs - (y)*(acols+2); //Calculate circle's center in pixels //计算圆心在输入图像中的坐标位置 float cx = (float)((x + 0.5f)*dp), cy = (float)(( y + 0.5f )*dp); float start_dist, dist_sum; float r_best = 0; int max_count = 0; // Check distance with previously detected circles //判断当前的圆心与之前确定作为输出的圆心是否为同一个圆心 for( j = 0; j < circles->total; j++ ) { //从序列中提取出圆心 float* c = (float*)cvGetSeqElem( circles, j ); //计算当前圆心与提取出的圆心之间的距离,如果两者距离小于所设的阈值,则认为两个圆心是同一个圆心,退出循环 if( (c[0] - cx)*(c[0] - cx) + (c[1] - cy)*(c[1] - cy) < min_dist ) break; } //如果j < circles->total,说明当前的圆心已被认为与之前确定作为输出的圆心是同一个圆心,则抛弃该圆心,返回上面的for循环 if( j < circles->total ) continue; // Estimate best radius //第二阶段 //开始读取圆周序列nz cvStartReadSeq( nz, &reader ); for( j = k = 0; j < nz_count; j++ ) { CvPoint pt; float _dx, _dy, _r2; CV_READ_SEQ_ELEM( pt, reader ); _dx = cx - pt.x; _dy = cy - pt.y; //步骤2.1,计算圆周上的点与当前圆心的距离,即半径 _r2 = _dx*_dx + _dy*_dy; //步骤2.2,如果半径在所设置的最大半径和最小半径之间 if(min_radius2 <= _r2 && _r2 <= max_radius2 ) { //把半径存入dist_buf内 ddata[k] = _r2; sort_buf[k] = k; k++; } } //k表示一共有多少个圆周上的点 int nz_count1 = k, start_idx = nz_count1 - 1; //nz_count1等于0也就是k等于0,说明当前的圆心没有所对应的圆,意味着当前圆心不是真正的圆心,所以抛弃该圆心,返回上面的for循环 if( nz_count1 == 0 ) continue; dist_buf->cols = nz_count1; //得到圆周上点的个数 cvPow( dist_buf, dist_buf, 0.5 ); //求平方根,得到真正的圆半径 //步骤2.3,对圆半径进行排序 icvHoughSortDescent32s( &sort_buf[0], nz_count1, (int*)ddata ); dist_sum = start_dist = ddata[sort_buf[nz_count1-1]]; //步骤2.4 for( j = nz_count1 - 2; j >= 0; j-- ) { float d = ddata[sort_buf[j]]; if( d > max_radius ) break; //d表示当前半径值,start_dist表示上一次通过下面if语句更新后的半径值,dr表示半径距离分辨率,如果这两个半径距离之差大于距离分辨率,说明这两个半径一定不属于同一个圆,而两次满足if语句条件之间的那些半径值可以认为是相等的,即是属于同一个圆 if( d - start_dist > dr ) { //start_idx表示上一次进入if语句时更新的半径距离排序的序号 // start_idx – j表示当前得到的相同半径距离的数量 //(j + start_idx)/2表示j和start_idx中间的数 //取中间的数所对应的半径值作为当前半径值r_cur,也就是取那些半径值相同的值 float r_cur = ddata[sort_buf[(j + start_idx)/2]]; //如果当前得到的半径相同的数量大于最大值max_count,则进入if语句 if( (start_idx - j)*r_best >= max_count*r_cur || (r_best < FLT_EPSILON && start_idx - j >= max_count) ) { r_best = r_cur; //把当前半径值作为最佳半径值 max_count = start_idx - j; //更新最大值 } //更新半径距离和序号 start_dist = d; start_idx = j; dist_sum = 0; } dist_sum += d; } // Check if the circle has enough support //步骤2.5,最终确定输出 //如果相同半径的数量大于所设阈值 if( max_count > acc_threshold ) { float c[3]; c[0] = cx; //圆心的横坐标 c[1] = cy; //圆心的纵坐标 c[2] = (float)r_best; //所对应的圆的半径 cvSeqPush( circles, c ); //压入序列circles内 //如果得到的圆大于阈值,则退出该函数 if( circles->total > circles_max ) return; } } } 9 参考文章 https://blog.csdn.net/qq_37059483/article/details/77916655 https://blog.csdn.net/m0_37264397/article/details/72729423 https://blog.csdn.net/zhaocj/article/details/50454847 https://blog.csdn.net/shanchuan2012/article/details/74010561 http://www.cnblogs.com/AndyJee/p/3805594.html https://blog.csdn.net/cy513/article/details/4269340 https://blog.csdn.net/poem_qianmo/article/details/26977557 http://homepages.inf.ed.ac.uk/rbf/HIPR2/hough.htm https://blog.csdn.net/m0_37264397/article/details/72729423 https://www.cnblogs.com/AndyJee/p/3805594.html